Secondo Nielsen, a maggio 2025 lo streaming ha superato per la prima volta la TV tradizionale negli USA, raggiungendo quasi il 45% del tempo di visione. Un sorpasso storico che ci dice molto più di quanto sembri: cambia il modo in cui ci informiamo, ci intratteniamo.
Negli ultimi anni, il modo in cui fruiamo dei contenuti video è cambiato radicalmente.
Secondo gli ultimi dati Nielsen, a maggio 2025 lo streaming ha rappresentato il 44,8% del tempo totale trascorso davanti allo schermo negli Stati Uniti. Per la prima volta, ha superato la somma delle due principali forme di televisione tradizionale: via cavo e in chiaro.
Un dato che non lascia spazio a dubbi: lo streaming non è più un’alternativa. È diventato il modo principale con cui le persone si informano, si intrattengono e scelgono cosa vedere.
Ma cosa significa davvero questo sorpasso?
Significa che non guardiamo più la TV come una volta. E non si tratta solo di tecnologia. È in atto un cambio culturale profondo. L’utente oggi è protagonista, sceglie quando, come e cosa guardare. Non esiste più il vincolo del palinsesti; non c’è più l’attesa per il programma delle 21. O delle 20:30 per chi lo ricorda. Tutto è on demand. Sempre.
Non è un caso che le piattaforme più popolari, da YouTube a Netflix, da Twitch a TikTok, siano diventate nel tempo ecosistemi di attenzione, capaci di trattenere gli utenti per ore grazie a un flusso continuo e personalizzato di contenuti.
Sorpasso dello streaming sulla Tv, un passaggio epocale
E questa trasformazione non riguarda solo l’intrattenimento.
Sempre più persone si informano tramite live streaming, notizie commentate in diretta, creator che costruiscono formati originali dove informazione e opinione si fondono. La differenza tra chi fa TV e chi fa streaming è ormai sempre più sottile. In molti casi, è del tutto svanita.
Non è più la TV a dettare il tempo dell’informazione o del racconto. È lo streaming a dettare il tempo dell’attenzione.
Un tempo si diceva “ci vediamo in TV”. Oggi si dice “seguimi in diretta” o “trovi tutto sul mio canale”.
È il trionfo della logica personalizzata, ma anche della disintermediazione portata forse all’estremo.
I creator parlano direttamente alle community, saltando tutta la filiera editoriale classica. E in questo scenario, la TV tradizionale – se non evolve – rischia di diventare marginale.
Naturalmente non tutti gli utenti sono migrati completamente. I contenuti sportivi in diretta e gli eventi di massa continuano ad avere un peso in TV. Ma anche lì, lo streaming avanza. Basti pensare a quanto sia centrale oggi Amazon Prime Video per il calcio o le mosse aggressive di Disney+ per accaparrarsi diritti sportivi.
In questo scenario, resta da capire se questo sorpasso è solo numerico o se diventerà strutturale, anche nel modo in cui raccontiamo il mondo.
Perché lo streaming è veloce, adattivo, iper-personalizzato. Ma rischia anche di essere più frammentato, più polarizzato, più schiavo dell’algoritmo.
La sfida oggi non è solo quella dell’audience. È la sfida della qualità. Se il tempo dell’attenzione si è spostato sulle piattaforme, la responsabilità di chi le popola è ancora più grande.
Vi invito ad ascoltare l’episodio sul mio canale YouTube, che vi invito a seguire, e anche su Spotify che trovate qui sotto.
Elon Musk giudicato responsabile di frode sui titoli per i tweet del 2022. Risarcimento stimato fino a 2,6 miliardi di dollari. È la prima sconfitta di Musk in un processo per frode finanziaria.
Si tratta della prima sconfitta di Musk in un processo per frode finanziaria. E, secondo le stime, potrebbe costargli fino a 2,6 miliardi di dollari in risarcimenti. Gli avvocati degli azionisti di Twitter ritengono che questo sia uno dei verdetti più grandi di una giuria in tema di frode finanziaria nella storia degli Stati Uniti.
Su queste pagine del blog ho seguito passo passo la vicenda dell’acquisizione di Twitter da parte di Elon Musk, fino a raccontare anche il momento della testimonianza in questo processo che vede imputato il proprietario di xAI. Questo verdetto conferma quello che avevo scritto già nel maggio 2022, quando gli azionisti depositarono la prima denuncia. E cioè che Musk stava giocando con questa acquisizione per fare in modo che il prezzo potesse scendere e fare in modo che la trattativa si ponesse in suo favore.
I tweet che a Musk potrebbero costare miliardi di dollari
Le due dichiarazioni giudicate materialmente false sono entrambi tweet pubblicati nel maggio 2022. Il primo, del 13 maggio, affermava che l’acquisizione di Twitter era “temporaneamente sospesa” in attesa di una verifica sulla percentuale di account bot.
Il secondo, del 17 maggio, sosteneva che l’operazione “non può procedere” finché il CEO di Twitter non avesse dimostrato che la percentuale di bot era inferiore al 5%, suggerendo che potesse essere superiore al 20%.
Dopo questi tweet le azioni Twitter crollarono di quasi il 18%, raggiungendo un minimo di 32,52 dollari, circa il 40% al di sotto del prezzo di acquisizione concordato di 54,20 dollari per azione.
La giuria ha invece assolto Musk da una dichiarazione rilasciata in un podcast, giudicandola un’opinione e non un’affermazione di fatto fuorviante. E soprattutto ha respinto l’accusa di aver orchestrato uno “schema” fraudolento sistematico contro gli investitori.
Elon Musk ha ingannato gli azionisti di Twitter, e li deve risarcire
Le ipotesi sulle cifre del risarcimento
La giuria ha calcolato danni compresi tra 3 e 8 dollari per azione per giorno di negoziazione durante l’intero periodo della classe, dal 13 maggio al 4 ottobre 2022. L’avvocato degli azionisti, Mark Molumphy, ha stimato il risarcimento totale in circa 2,1 miliardi di dollari per le perdite azionarie più 500 milioni per le stock option, per un totale massimo di circa 2,6 miliardi di dollari.
L’importo finale dipenderà dal numero di azionisti che presenteranno richiesta di risarcimento attraverso il procedimento di class action. Questa comprende tutti gli investitori che hanno venduto titoli Twitter tra il 13 maggio e il 4 ottobre 2022, data in cui Musk annunciò che avrebbe proceduto con l’acquisizione al prezzo originale, facendo balzare il titolo del 22% in una sola seduta.
Nonostante la cifra imponente, diverse fonti hanno osservato che il risarcimento avrebbe un impatto minimo sul patrimonio personale di Musk, stimato tra 650 e 839 miliardi di dollari a seconda dell’indice utilizzato.
La difesa di Musk annuncia l’appello
La reazione del team legale di Musk è stata rapida. In una dichiarazione rilasciata subito dopo il verdetto gli avvocati di Musk hanno affermato di considerare la decisione “un ostacolo temporaneo” e di attendere “piena soddisfazione in appello”.
Gli avvocati hanno anche ricordato le recenti vittorie di Musk in cause separate: una vittoria in appello in Delaware relativa al compenso Tesla e un’altra vittoria in un tribunale del Texas lo stesso giorno del verdetto.
Durante il processo, durato circa tre settimane iniziato il 2 marzo 2026, Musk stesso testimoniato il 4 marzo scorso. Le sue dichiarazioni più notevoli includono l’ammissione che i tweet fossero stati imprudenti: “Se questo fosse un processo su tweet stupidi, mi dichiarerei colpevole”. Musk ha però insistito di non aver mai dichiarato l’annullamento dell’operazione e di non poter controllare le decisioni di vendita degli investitori.
Cosa succede adesso
La tempistica post-verdetto si articola su due binari paralleli. Sul fronte del risarcimento gli avvocati degli azionisti hanno stimato che serviranno circa 90 giorni per attivare la procedura di amministrazione dei reclami, seguiti da ulteriori mesi per l’elaborazione delle richieste individuali.
Complessivamente gli azionisti che hanno portato Musk in tribunale per frode finanziaria potrebbero ricevere i pagamenti entro sei mesi dal verdetto.
Sul fronte dell’appello, gli avvocati di Musk confermano l’intenzione di impugnare il verdetto presso la Corte d’Appello, il che potrebbe estendere significativamente i tempi.
Un procedimento parallelo rilevante è la causa SEC contro Musk, intentata nel gennaio 2025 per la mancata tempestiva comunicazione della sua quota azionaria superiore al 5% in Twitter nel marzo 2022. Al 17 marzo 2026 le parti erano in trattative per un possibile accordo. La SEC chiede una multa civile e la restituzione dei circa 150 milioni di dollari che Musk avrebbe risparmiato acquistando azioni prima della divulgazione obbligatoria.
E va avanti l’indagine parigina su X e Elon Musk
E mentre a San Francisco la giuria emetteva il verdetto, da Parigi arrivava un’altra tegola.
L’ipotesi è che Musk abbia tentato di gonfiare artificialmente il numero di utenti di X in vista di una possibile quotazione in borsa. Le informazioni raccolte dai procuratori francesi, emerse nel corso di un’indagine avviata in Francia all’inizio del 2025, suggeriscono che la controversia sui deepfake generati da Grok, il chatbot di X, potrebbe essere stata alimentata deliberatamente per aumentare la valutazione della piattaforma.
Il tutto in un momento cruciale, con l’IPO della nuova entità nata dalla fusione di SpaceX e xAI prevista per giugno 2026, mentre X stava perdendo slancio.
Cosa dice la sentenza che condanna Musk al risarcimento
La sentenza stabilisce che i tweet di un individuo con la capacità di influenzare i mercati possono essere trattati alla stregua di dichiarazioni finanziarie formali, ai fini della responsabilità per frode sui titoli. Come ricordato qui, è la prima volta che una giuria ritiene Musk personalmente responsabile per l’impatto dei suoi tweet sul mercato azionario.
Ma il verdetto del 20 marzo 2026 segna tre novità fondamentali.
È la prima condanna di Musk per le conseguenze dei suoi tweet, una frattura nel mito dell’invulnerabilità legale di “Teflon Elon”, il soprannome che Musk si è guadagnato in riferimento al “teflon”, il rivestimento antiaderente delle padelle per intenderci.
Con un risarcimento stimato fino a 2,6 miliardi di dollari stabilisce un nuovo record per i verdetti di giuria in cause per frode sui titoli negli Stati Uniti. E crea un precedente sulla responsabilità per dichiarazioni sui social media che possono influenzare i mercati finanziari, con implicazioni che vanno ben oltre il caso specifico.
In ogni caso, la battaglia legale è lontana dalla conclusione. L’appello annunciato dagli avvocati potrebbe prolungare il contenzioso per mesi, e l’assenza di una condanna per “schema fraudolento” offre alla difesa una base su cui costruire la propria impugnazione.
Resta da vedere se questo verdetto segnerà davvero un limite al potere che alcuni individui esercitano sui mercati finanziari attraverso messaggi pubblici, o se confermerà che nell’era dei social media la linea tra comunicazione e manipolazione rimane indefinita.
Perché è questo il punto nevralgico di questa vicenda.
Il World Happiness Report 2026 dedica l’edizione al rapporto tra social media e benessere. I dati confermano quello che sapevamo da tempo: le piattaforme guidate da algoritmi stanno erodendo la salute mentale dei più giovani. In 85 paesi su 136 i giovani sono più felici di vent’anni fa, ma in Occidente il trend si è invertito e l’Italia non fa eccezione.
È inutile girarci intorno, i social media hanno smesso di essere social. Cioè le piattaforme hanno perso molto, in questi anni, del significato della parola “social”, intesa come connessione tra le persone.
E quel momento coincide con l’inizio del declino del benessere giovanile. Non si tratta di una coincidenza, ma di una correlazione diretta. Ed è un meccanismo che il World Happiness Report 2026, pubblicato in occasione della Giornata Internazionale della Felicità, 20 marzo 2026, documenta con una precisione che lascia poco spazio alle interpretazioni.
Il rapporto di quest’anno è diverso dai precedenti, infatti non si limita a stilare la classifica dei paesi più felici. Dedica l’intera edizione a una domanda che riguarda centinaia di milioni di adolescenti: cosa stanno facendo le piattaforme digitali al loro benessere? La risposta arriva da nove capitoli firmati da alcuni dei maggiori esperti mondiali, tra cui Jonathan Haidt, Jean Twenge e Cass Sunstein.
In 85 paesi i giovani stanno meglio, in Occidente peggio
Cominciamo col dire che in 85 paesi, su 136 analizzati, i giovani sotto i 25 anni sono più felici oggi rispetto a vent’anni fa. Il benessere giovanile globale, nel suo complesso, è aumentato. Ma fanno eccezione i paesi occidentali, e in particolare quelli anglofoni.
Negli Stati Uniti, Canada, Australia e Nuova Zelanda il benessere degli under 25 è crollato di 0,86 punti su una scala da 0 a 10 negli ultimi vent’anni. Quasi un punto intero. È un dato rilevante, che segna una frattura generazionale ormai evidente.
E l’Europa occidentale, Italia compresa, segue lo stesso trend, anche se con intensità leggermente inferiore.
Il WHR 2026 identifica con chiarezza il principale indiziato, vale a dire l’uso intensivo dei social media, in particolare quelli guidati da feed algoritmici.
Per essere molto chiari in questo contesto, il problema non è internet in sé. Il rapporto distingue nettamente tra attività online che aumentano il benessere e attività che lo erodono. Comunicare, informarsi, imparare, creare contenuti sono associati a maggiore soddisfazione di vita. Consumare passivamente social media, fare gaming e navigare senza scopo sono associati a valutazioni di vita più basse.
Il benessere mentale dei giovani è ostaggio degli algoritmi
Correlazione che cambia con l’età: negativa per la Gen Z, positiva per i Boomer
Per quanto riguarda il capitolo 8 del rapporto, c’è un passaggio che chiarisce meglio la questione. I ricercatori hanno analizzato quattro cicli dell’European Social Survey, coprendo 30 paesi europei dal 2016 al 2024. E hanno scoperto che la relazione tra uso di internet e benessere varia drasticamente in base all’età.
Per la Generazione Z la correlazione è fortemente negativa, diventa poi moderatamente negativa per i Millennial, ed è vicina allo zero per la Generazione X. Per i Baby Boomer è leggermente positiva.
In altre parole, lo stesso strumento produce effetti opposti a seconda di chi lo usa e di come lo usa. I giovani europei, soprattutto le ragazze, ne stanno pagando il prezzo più alto.
Il rapporto documenta che le fondamenta sociali ed emotive del benessere mentale si sono deteriorate soprattutto per i giovani europei, in particolare in Europa occidentale. Fiducia interpersonale, fiducia nelle istituzioni, percezione dell’attività sociale, frequenza degli incontri di persona: tutti questi indicatori mostrano i cali più marcati per le donne della Gen Z e dei Millennial.
La distinzione cruciale: piattaforme per connettersi e piattaforme per consumare
Il WHR 2026 introduce una distinzione abbastanza chiara a tutti in questo momento storico. Le piattaforme guidate da contenuti curati algoritmicamente tendono a mostrare un’associazione negativa con il benessere. Quelle invece progettate per facilitare le connessioni sociali mostrano un’associazione chiaramente positiva con la felicità.
Non è solo questione di tempo trascorso online, ma riguarda davvero come quel tempo viene impiegato.
I dati PISA su quindicenni di 47 paesi mostrano che la soddisfazione è massima in presenza di bassi livelli di uso delle piattaforme social media e diminuisce progressivamente con l’aumentare delle ore. Ma il tipo di uso conta quanto la quantità: seguire molte piattaforme, usare i social come fonte primaria di notizie, seguire influencer sono tutti comportamenti associati a stress più alto, sintomi depressivi più frequenti e maggiore probabilità di sentirsi peggio dei propri genitori.
Quello che Meta sapeva e non ha detto
Il capitolo 3, firmato da Jonathan Haidt e Zach Rausch, presenta sette linee di evidenza a sostegno di una tesi molto chiara: i social media stanno danneggiando gli adolescenti al punto da causare cambiamenti misurabili.
Si tratta della conclusione di un’analisi che incrocia testimonianze dirette di giovani, genitori e insegnanti, documenti aziendali interni, studi correlazionali, ricerche longitudinali, esperimenti di riduzione dell’uso e esperimenti naturali.
Ma la parte più interessante riguarda quello che le aziende tech stesse sapevano.
A gennaio 2026 Haidt e colleghi della NYU hanno lanciato MetasInternalResearch.org, un archivio di 31 studi interni condotti da Meta tra il 2018 e il 2024. Documenti ottenuti grazie anche alle rivelazioni di Frances Haugen, alle testimonianze di Arturo Béjar e ai procedimenti legali avviati dai procuratori generali statali americani.
Uno studio interno, si chiamava Project Mercury, era interessante perché era un esperimento randomizzato e controllato, condotto tra il 2019 e il 2020 in collaborazione con Nielsen. Gli utenti assegnati casualmente a disattivare Facebook e Instagram per una settimana riportarono minori livelli di depressione, ansia, solitudine e tendenza al confronto sociale. Meta chiuse il progetto invece di pubblicarlo.
L’onda legislativa che parte dall’Australia
Come sappiamo, e lo abbiamo raccontato su queste pagine e sul video podcast, l’Australia ha fatto da apripista con l’Online Safety Amendment Act, entrato in vigore a dicembre 2025. Una legge che vieta l’accesso ai social media agli under 16, senza possibilità di consenso parentale. Le dieci piattaforme coperte dal divieto sono Facebook, Instagram, Threads, Snapchat, TikTok, YouTube, X, Reddit, Twitch e Kicke e nel primo mese di applicazione sono stati rimossi, disattivati o limitati 4,7 milioni di account.
Ora l’onda legislativa su questo tema si sta propagando. La Francia ha approvato il divieto per gli under 15 all’Assemblea Nazionale nel gennaio 2026. Spagna e Paesi Bassi hanno annunciato divieti per gli under 16 a febbraio. La Danimarca ha raggiunto un accordo per il limite a 15 anni. La Germania sta costruendo un consenso trasversale per il divieto agli under 16. Negli Stati Uniti, 28 stati hanno emanato leggi per scuole senza telefoni nel solo 2025.
Il collegamento con l’intelligenza artificiale che nessuno vuole vedere
Ma c’è un passaggio ulteriore che il WHR 2026 non affronta direttamente, ma che Haidt ha reso esplicito in diverse interviste recenti.
In un’intervista a NPR di quest’anno lo psicologo ha espresso un concetto che condivido e che ho espresso, riferendomi all’aspetto delle regole, anche io in questi ultimi due anno. In sostanza, con i social media abbiamo lasciato che le piattaforme entrassero nella vita dei giovani senza capire cosa stava facendo al loro benessere. Con l’intelligenza artificiale stiamo per ripetere lo stesso errore, ma questa volta sarà più rapido e più devastante, perché parliamo di qualcosa che rischia di sostituire le relazioni umane.
Haidt vede la battaglia sui social media come un test. Se le democrazie riescono a regolare le piattaforme social, avranno la credibilità e gli strumenti per regolare l’IA prima che sia troppo tardi. Ma non abbiamo cinque anni, ha aggiunto, dobbiamo fare in modo che questo accada entro il 2026.
I numeri ci dicono che il 72% degli adolescenti americani ha già usato un “companion AI” almeno una volta. I “companion AI” sono piattaforme come Replika, Character.AI, e in parte anche ChatGPT usato in quel modo. Applicazioni che i giovani usano per parlare, per sfogarsi, per avere qualcuno che risponde sempre, che non giudica, che è sempre disponibile.
Il rischio è che i chatbot empatici sostituiscano le relazioni umane proprio nella fase della vita in cui quelle relazioni sono più formative.
Il World Happiness Report 2026 nel suo rapporto non offre soluzioni definitive, ma ci mette davanti i dati che mostrano quanto le piattaforme oggi incidono sul benessere e sulla felicità delle persone.
Come ha scritto Jan-Emmanuel De Neve, direttore del Wellbeing Research Centre di Oxford e co-curatore del rapporto, è chiaro che dovremmo cercare il più possibile di rimettere il social dentro i social media.
Questa è la parte più difficile, in un momento in cui le piattaforme sono sempre più animate algoritmo del proprietario che lascia sempre meno spazio alle relazioni vere e autentiche.
Non sarà facile ricostruire questo aspetto delle piattaforme, più facile cambiare totalmente approccio. Bisogna abbandonare l’idea che le piattaforme siano ancora “contenitori di esistenze”, come sostenevo qualche anno fa, e trasformale il luoghi dove serve molta consapevolezza e responsabilità.
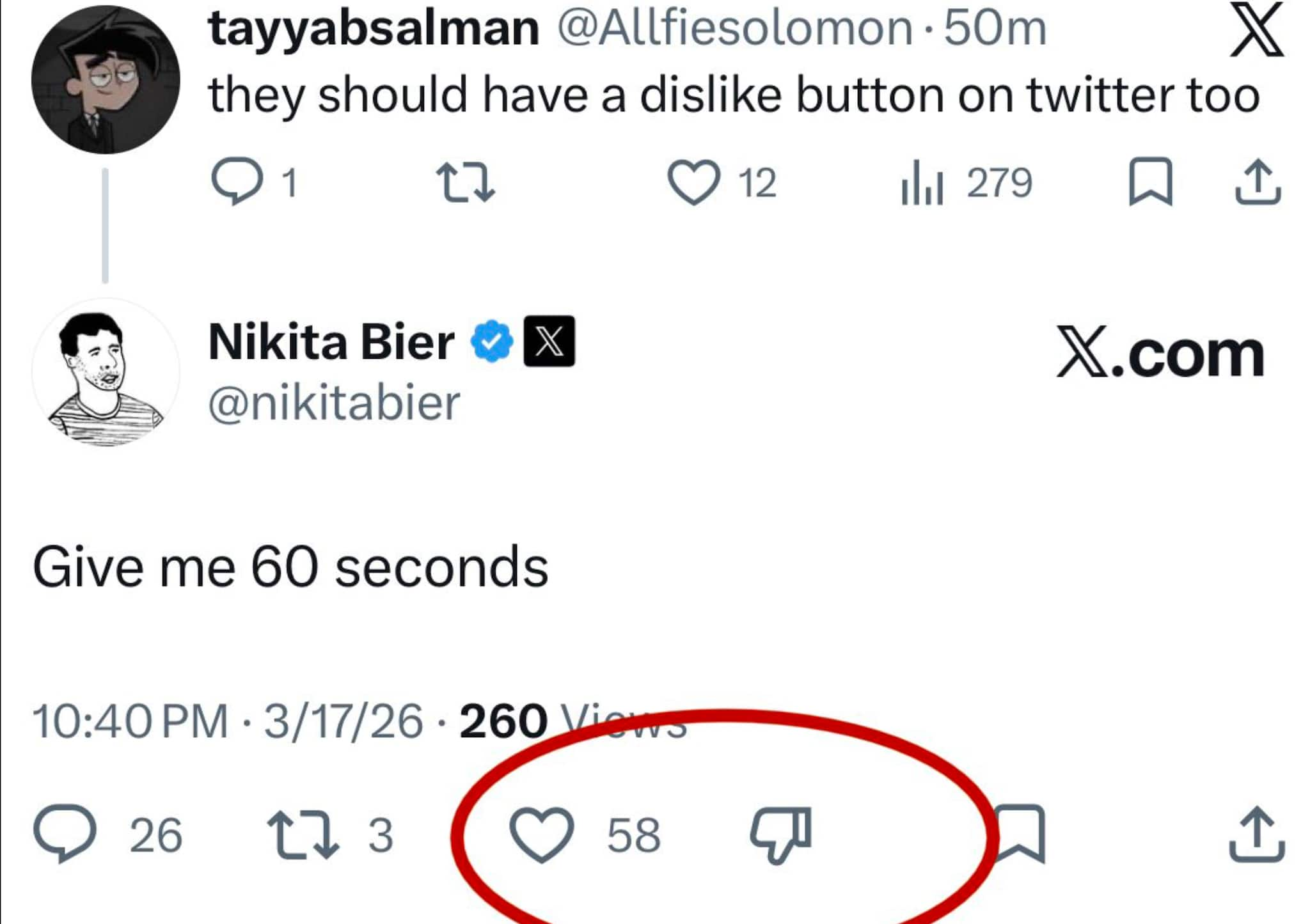
Nikita Bier, responsabile di prodotto di X, ha annunciato il rilascio del tasto dislike sulle risposte con una battuta che sembrava uno scherzo. In realtà la funzionalità era già attiva per alcuni utenti. Il conteggio resta privato, ma il segnale arriva direttamente all’algoritmo di ranking.
C’è un modo particolare in cui le piattaforme social introducono le novità più attese. Annunci studiati, comunicati stampa, roll-out graduali con tanto di post enigmatici. E poi c’è il modo di X, quello con cui ha introdotto il tasto dislike sulle risposte: con una battuta che nessuno, inizialmente, ha preso sul serio. Siamo su X e non poteva essere diversamente.
Tutto è partito quando un utente ha chiesto a Nikita Bier, Head of Product di X, se fosse possibile aggiungere un pulsante di dislike per le risposte. La risposta di Bier è stata veloce e lapidaria: “Give me 60 seconds“.
Otto minuti dopo, i primi screenshot mostravano l’icona del pollice verso già attiva su alcuni account. Non si trattava più di ironia e scherzo, era un’attivazione istantanea di una funzionalità che, con ogni probabilità, era già pronta e aspettava solo di essere accesa e aspettava solo il momento giusto.
Ma la cosa interessante non è la velocità del rilascio, è il motivo per cui X ha deciso di procedere proprio ora.
Bier: le risposte sono il peggior prodotto di X
Nikita Bier non ha usato mezzi termini. In un post pubblicato poco dopo l’attivazione, ha scritto che l’algoritmo delle risposte è “attualmente il peggior prodotto dell’azienda” e che “non c’è logica, non c’è segnale, solo spazzatura”.
Un’ammissione che spiega perché il dislike è stato introdotto esclusivamente sulle risposte e non sui post principali.
Da mesi la sezione commenti di X è invasa da bot crypto, spam generato da agenti AI, e da tattiche di engagement farming e risposte completamente fuori tema che finiscono per inquinare l’esperienza (già molto difficile) di chi cerca un minimo di confronto che su X è sempre più un miraggio.
Il tasto dislike serve proprio a questo, ossia a dare all’algoritmo un segnale immediato per mettere in cima le risposte apparentemente di valore e spingere in basso, o nascondere del tutto, il grande rumore di fondo.
Il dislike su X, ecco come funziona
La funzionalità è semplice e appare sotto le risposte, non sui post principali. È rappresentato da un’icona grigia, un pollice verso, posizionato accanto ai tasti di reactions. I conteggi sono assolutamente privati: nessuno può vedere quante volte una risposta è stata segnata come negativa, neanche l’autore stesso.
Quando si clicca sul dislike, in alcuni casi si potrebbe aprire un piccolo spazio di feedback con opzioni strutturate in questo modo: “Spam”, “Generato da AI”, “Scorretto o fuorviante”, “Fuori tema”.
Stiamo parlando quindi di un segnale privato che finisce dritto nell’algoritmo di ranking delle conversazioni. X lo usa per decidere quali risposte mostrare in alto e quali spingere verso il basso.
Bier ha precisato che il tasto non funzionerà come il downvote di Reddit, dove i voti negativi sono pubblici e possono determinare il crollo della visibilità di un commento. Qui il segnale serve esclusivamente al ranking e alla personalizzazione della sezione risposte, senza esporre metriche che potrebbero alimentare dinamiche di attacchi coordinati o risposte di massa.
Come sarà il tasto dislike su X
La strategia anti-spam: rendere lo spam economicamente insostenibile
L’obiettivo di questa mossa, come dichiarato da Bier, non dovrebbe fermarsi al miglioramento dell’esperienza di chi legge le risposte. Nei prossimi 30 giorni, ha spiegato, chi produce spam su X guadagnerà sempre meno. Il dislike è solo una parte di un intervento più ampio che prevede anche limitazioni geografiche sulle risposte e altri strumenti per contrastare gli abusi.
Se le risposte spam vengono sistematicamente abbassate in termini di visibilità dall’algoritmo grazie ai segnali negativi degli utenti, chi le produce non ottiene più visibilità. E se non ottiene visibilità, non guadagna. Il modello di business dei bot che intasano le conversazioni per generare impressions potrebbe essere così colpito alla radice.
Il caso precedente di YouTube
X non è la prima piattaforma a sperimentare con i segnali negativi. E la scelta di mantenere privati i conteggi sembra aver recepito le lezioni di chi ci ha provato prima.
Secondo YouTube, l’esperimento aveva mostrato una riduzione significativa dei comportamenti di attacco mirato. L’algoritmo continuava a usare il segnale internamente per le raccomandazioni, ma la negatività pubblica si era in parte spostata nei commenti.
Reddit e il rischio delle camere dell’eco
Reddit rappresenta l’altra piattaforma che utilizza ormai questo strumento.
Il downvote è pubblico, in grado far crollare drasticamente la visibilità di un commento. Studi accademici hanno documentato come un singolo voto negativo possa influenzare a cascata i voti successivi: chi arriva dopo tende a conformarsi al giudizio già espresso.
Il risultato è una moderazione efficace contro spam e contenuti fuori tema, ma anche un effetto echo-chamber, di camera d’eco dove le opinioni in genere minoritarie vengono sistematicamente affossate.
X sembra prendere spunto da queste due esperienze. Rendendo i conteggi privati, come ricordato prima, il segnale arriva all’algoritmo.
X e il dislike, rilascio graduale
Al momento il rollout è limitato e lato server, infatti alcuni utenti lo vedono già, altri no. Classico rilascio asimmetrico che X ha adottato per molte delle sue novità recenti. Chi lo ha già attivo riporta che la sezione risposte appare effettivamente più pulita, con meno spam in evidenza.
X introduce il tasto dislike nelle risposte, ecco come funziona
Una mossa che è anche un’incognita
Diciamolo, per come stanno le cose sulla piattaforma di Elon Musk questa sicuramente non risolverà tutti i problemi, ma prova ad affrontare quello che lo stesso responsabile di prodotto ha definito il suo lato più debole.
Resta da vedere se la promessa di Bier si realizzerà, soprattutto quando punta a rendere lo spam economicamente insostenibile entro 30 giorni.
Più interessante da vedere è come gli utenti useranno questo nuovo strumento, se per migliorare la qualità delle conversazioni o per altri scopi che X non ha previsto.
Meta sta testando la possibilità di inserire link cliccabili nelle didascalie dei post di Instagram, una delle funzioni più richieste. Ma sarebbe previsto solo per gli abbonati a Meta Verified e solo per 10 link al mese. Ma funzionerà?
La notizia è che Instagram sta testando i link cliccabili nelle didascalie dei post. Si tratta di una delle funzionalità più richieste di sempre e ora arriva la fase di test.
La conferma arriva direttamente da Instagram che si dice “entusiasta di testare quale nuovo valore questa funzionalità possa portare”. Per ora si tratta di un test limitato ad alcuni creator iscritti a Meta Verified, e sembra con un tetto massimo di 10 link al mese.
È una di quelle notizie che sulla carta dovrebbero entusiasmare un po’ tutti. I link nelle didascalie sono la funzione più richiesta della storia di Instagram, quella che Adam Mosseri ha sempre negato con la stessa motivazione. Fu proprio lui qualche anno fa a sostenere che aggiungere link avrebbe spostato la piattaforma“lontano dai creator e verso i publisher”, trasformando Instagram in qualcosa di diverso da ciò che è sempre stato. E invece ora Meta cambia idea considerando la funzione solo per chi paga, in buona sostanza.
Il paradosso dell’algoritmo che penalizza i link
Ora, detta così sembra bellissimo, ma c’è un problema di fondo che questa novità non risolve, anzi evidenzia. Oltre che un problema all’atto pratico, c’è da fare anche una considerazione sulla contraddizione che questa mossa pone.
Le piattaforme di Meta, Instagram inclusa, penalizzano sistematicamente i contenuti che contengono link esterni. È una dinamica nota a chiunque gestisca pagine e profili professionali: un post con un link ottiene meno visibilità di un post senza. L’algoritmo preferisce trattenere gli utenti sulla piattaforma, senza permettere loro di poter approfondire altrove.
E allora cosa sta vendendo Meta agli utenti verificati? Una funzione che il suo stesso sistema di distribuzione rende meno efficace. È come vendere un biglietto del treno che parte in orario sapendo poi che arriverà sempre in ritardo. Il creator paga 13,99 euro (da web, diventando 16,99 da mobile) al mese per poter inserire link che l’algoritmo poi tenderà comunque a penalizzare.
Il limite di 10 link mensili, presentato come una forma di equilibrio, è in realtà una sorta di ammissione del problema e della colpa insieme.
Se i link non creassero tensione con il modello di distribuzione, perché limitarli? Meta sa che troppi link trasformerebbero il feed in qualcosa che non vuole gestire, ma sa anche che qualche link, venduto come una sorta privilegio, può aiutare sicuramente ad aumentare le entrate.
Instagram testa i link nei post, ma solo per gli account verificati
I link nelle Stories funzionano, forse
L’unico spazio su Instagram dove i link apparentemente funzionano senza penalizzazioni particolari sono le Stories. Ma c’è una differenza strutturale non da poco: le Stories scompaiono dopo 24 ore mentre i post restano.
Un link in una Story è un’eccezione temporanea; un link in un post è un elemento permanente del profilo. Se Meta aprisse davvero ai link nei post senza conseguenze algoritmiche, smonterebbe la logica che tiene in piedi l’intero sistema di distribuzione organica.
Ma servirà davvero?
La domanda da porsi non è se la funzione arriverà, ma se servirà a qualcosa.
Per i creator che producono contenuti e vogliono portare traffico ai propri siti, video, blog o newsletter, il valore reale dipenderà da quanto l’algoritmo permetterà a quei post di circolare. E su questo non vi è alcuna certezza.
Se la visibilità resterà penalizzata, i 10 link mensili diventeranno nel breve termine 10 occasioni sprecate.
Cosa accadrà per i brand al momento non è chiaro. Il test riguarda per ora gli account creator, ma non è stato specificato cosa accadrà per gli account business delle aziende.
Meta Verified e i link, nuova fonte di ricavi
Il contesto in cui arriva questo test è quello di un’azienda che cerca nuove fonti di ricavo. Meta Verified ha già portato nelle casse dell’azienda centinaia di milioni di dollari. Secondo le stime basate sui dati finanziari dell’ultimo trimestre 2025, gli abbonati paganti su Facebook e Instagram potrebbero essere circa 30 milioni. Una funzione come i link nelle didascalie serve esattamente a questo, a convincere altri creator a pagare.
Tra le righe si legge che Meta sta costruendo un modello in cui le funzioni un tempo negate diventano prodotti a pagamento. Non cambia le regole e non nega evoluzione, semplicemente le trasforma in funzionalità a pagamento. E questo, come si diceva all’inizio, relativamente all’inserimento dei link, arrivano in un momento storico in cui proprio i link sono sempre più demotivati dalle piattaforme.
Una sorta di paradosso.
Resta da vedere se questo test si trasformerà in una funzione stabile (come è probabile che sarà) e, soprattutto, se i link nei post riusciranno davvero a portare traffico senza essere soffocati dall’algoritmo (tutto da vedere, ovviamente).
Per ora, la sensazione è che Meta stia vendendo una promessa più che una soluzione. Staremo a vedere.
X ha presentato alla Commissione UE le misure correttive sul sistema di verifica della spunta blu, tre mesi dopo la multa di 120 milioni di euro per violazione del Digital Services Act.
Tre mesi dopo la prima sanzione della storia ai sensi del Digital Services Act, X ha comunicato a Bruxelles le misure correttive sul sistema delle spunte blu. La Commissione UE valuterà se le proposte sono sufficienti a risolvere il problema del design ingannevole che aveva portato alla multa di 120 milioni di euro.
La decisione di X sulla spunta blu dopo la multa dell’UE
La Commissione ha fatto sapere che valuterà attentamente le proposte prima di pronunciarsi. Questo significa che la partita non è ancora chiusa. Infatti, Bruxelles potrebbe accettare le misure, chiedere modifiche, o ritenerle insufficienti.
Ma il fatto stesso che X abbia presentato un piano correttivo, invece di impugnare la sanzione, rappresenta un cambio di rotta rispetto alla retorica dello scontro che aveva caratterizzato la reazione iniziale di Musk.
X cede all’UE sulla spunta blu, in arrivo le misure correttive dopo la multa DSA
Perché la spunta blu di X viola il Digital Services Act
Come già ricordato, il problema centrale riguarda il cambiamento di significato della spunta blu senza un adeguato cambiamento del simbolo visivo.
Quando la piattaforma si chiamava ancora Twitter, la spunta blu certificava che un account apparteneva davvero alla persona o all’organizzazione dichiarata. Era un sistema gratuito, gestito dalla piattaforma, che verificava l’identità prima di assegnare il simbolo.
Dopo l’acquisizione da parte di Musk nel 2022, la spunta blu è diventata un servizio a pagamento accessibile a chiunque sottoscrivesse un abbonamento X Premium. La Commissione Europea ha stabilito che questo costituisce un dark pattern, ovvero un design ingannevole vietato dall’articolo 25 del DSA.
Quindi, X ha mantenuto lo stesso simbolo pur cambiandone radicalmente il significato, sfruttando l’associazione logica consolidata negli utenti tra spunta blu e identità verificata.
La decisione della Commissione, resa pubblica a fine gennaio grazie al rilascio da parte della House Judiciary Committee statunitense, descrive la trasformazione in termini precisi: X è passata da un sistema di conferma proattiva ed ex ante dell’identità, a uno in cui lo status verificato viene distribuito ad abbonati anonimi, con un approccio almeno parzialmente reattivo agli abusi di impersonificazione.
La multa di 120 milioni e le tre violazioni contestate
La sanzione di 120 milioni di euro, comminata il 5 dicembre 2025, lo ricorderete, riguardava tre violazioni distinte degli obblighi di trasparenza previsti dal Digital Services Act. La prima, quella sulla spunta blu, aveva un termine di 60 giorni per la presentazione delle misure correttive. Le altre due, relative all’opacità del registro pubblicitario e al mancato accesso ai dati per i ricercatori, avevano un termine di 90 giorni.
Si tratta della prima sanzione della storia applicata a una Very Large Online Platform (VloP) ai sensi del DSA. L’importo, calcolato sulla base della natura delle violazioni, della loro gravità e della loro durata, è stato definito dalla Commissione come modesto ma proporzionato, ben al di sotto del massimo previsto dal regolamento che può arrivare fino al 6% del fatturato globale annuo.
La scelta di X di presentare misure correttive invece di impugnare la sanzione in tribunale rafforza la credibilità del DSA come strumento di applicazione delle norme.
Per la Commissione UE, la posta in gioco era alta: una lunga battaglia legale avrebbe potuto esporre debolezze procedurali, rallentare l’applicazione delle norme, dare argomenti a chi sostiene che l’UE regola troppo e innova troppo poco.
Invece, almeno su questo fronte, si è arrivati a una forma di adeguamento. Non significa che il DSA abbia vinto in modo definitivo. Significa che il primo vero test del regolamento europeo sui servizi digitali si è concluso con una piattaforma che sceglie di conformarsi piuttosto che resistere.
Le tensioni tra USA e UE sulla regolamentazione delle piattaforme
Questa svolta tecnica non cancella le tensioni politiche tra Washington e Bruxelles.
A dicembre, il vicepresidente americano J.D. Vance aveva attaccato duramente la decisione della Commissione, parlando di attacco alla libertà di parola e alle aziende americane. La retorica dello scontro tra modello europeo di regolamentazione e visione americana di libertà digitale resta accesa.
Ma una cosa è la retorica pubblica, un’altra sono le scelte operative. La decisione di X di adeguarsi piuttosto che resistere suggerisce che il costo di ignorare le regole europee è considerato troppo alto, anche per chi ha le risorse per sostenere battaglie legali prolungate e anche in un momento di forte tensione politica transatlantica.
Cosa resta da capire sul futuro della spunta blu in UE
La Commissione non ha comunicato tempi per la valutazione delle misure proposte da X. Non sappiamo se la piattaforma intenda modificare il sistema delle spunte blu solo per gli utenti europei o a livello globale. E non sappiamo se il cambiamento sarà sostanziale, con un ritorno a forme di verifica dell’identità, o se si limiterà a interventi sull’interfaccia per chiarire il significato del simbolo.
Restano aperte anche le altre indagini su X. La Commissione UE sta ancora esaminando la gestione dei contenuti illegali e il funzionamento dell’algoritmo di raccomandazione, con particolare attenzione ai rischi di radicalizzazione. Su questi fronti non sono ancora state raggiunte conclusioni preliminari.
Per ora, quello che possiamo dire è che il primo round tra X e il DSA si è concluso con un adeguamento, invece di uno scontro. Resta da vedere se questa scelta segna un cambio di strategia duraturo o si tratta di una pausa tattica. Molto probabile che X, e quindi Elon Musk, abbia agito sapendo bene che il mercato UE resta ancora importante per la piattaforma.
Meta ha acquisito Moltbook, il social network dove solo gli agenti IA possono interagire. Il vero obiettivo non è la piattaforma, ma è l’idea. Quindi costruire una mappa di agenti IA che in futuro compiranno azioni per gli utenti.
Il 10 marzo 2026 Meta acquisisce Moltbook, forse ricorderete tutti la piattaforma dove solo gli agenti AI possono pubblicare contenuti, commentare e interagire tra loro. Un social network di soli agenti IA.
In molti, dopo questo annuncio si sono chiesti come mai Meta dovrebbe interessarsi ad una operazione come questa, per farne cosa. Ora, a prima vista, in effetti, sembra una mossa bizzarra, lontana dal business di Zuckerberg. Lo stesso Andrew Bosworth, il responsabile tecnico di Meta, aveva definito Moltbook “non particolarmente interessante”. E allora perché Meta compra questa piattaforma?
La risposta sta in quello che Moltbook rappresenta, non in quello che è in realtà.
Infatti, Meta non ha comprato un social network per chatbot, ma ha comprato l’idea di creare una sorta di anagrafe degli agenti AI. Vale a dire un sistema dove ogni agente IA è identificato, verificato e collegato a un proprietario umano reale, un proprietario umano.
Come sappiamo, oggi gli agenti AI non hanno un modo standard per presentarsi l’uno all’altro e dimostrare per conto di chi lavorano. Moltbook ha risolto quel problema. E in un futuro dove miliardi di agenti AI negozieranno, acquisteranno e comunicheranno per conto nostro, chi controlla questa sorta anagrafe finirà per controllare il flusso economico.
Ecco perché Meta ha acquisito Moltbook
Moltbook è nato alla fine di gennaio 2026 da un esperimento di Matt Schlicht, un imprenditore che ha costruito l’intera piattaforma insieme al suo assistente IA personale, senza scrivere una riga di codice.
L’idea era ambiziosa e cioè quella di creare una sorta Reddit dove solo gli agenti IA possono partecipare. Ricorderete perché se ne è parlato molto, in poche settimane ha attirato 2,8 milioni di agenti registrati, 19.000 comunità tematiche, 13 milioni di commenti. Ma dietro questi grandi numeri c’era qualche crepa.
Un’indagine di Wiz Research scoprì che 1,5 milioni di quegli agenti appartenevano in realtà ad appena 17.000 persone. Gli esperti del settore i divisero: tanti lodavano il progetto, ma tanti altri lo definivano un vero disastro.
La risposta a questo apparente paradosso arriva da un messaggio interno di Vishal Shah, vicepresidente di Meta, visto da Axios: “Il team di Moltbook ha dato agli agenti un modo per verificare la propria identità e connettersi tra loro per conto dei proprietari umani. Questo crea un registro dove gli agenti sono verificati e legati ai loro proprietari“. In altre parole, non importa che la piattaforma fosse piena di problemi. Importa l’idea che ha messo in pratica.
Per comprendere il valore di questa idea basta pensare a cosa ha fatto Facebook vent’anni fa. Zuckerberg ha costruito una mappa di tutte le connessioni tra le persone, chi conosce chi, chi è amico di chi. Quella mappa è diventata la base del suo grande impero oggi. Con questa acquisizione Meta prova a costruire qualcosa di simile per gli agenti AI: una mappa di come gli agenti IA sono connessi tra loro e di quali azioni possono compiere l’uno per conto dell’altro.
Perché Meta ha acquisito Moltbook, qual è la strategia
A cosa servono i 135 miliardi di dollari in chip MTIA e infrastrutture AI
L’acquisizione di Moltbook acquista senso solo riusciamo ad avere un quadro complessivo.
Meta sta portando avanti una grande campagna di investimenti tra le più ingenti del settore.
Tanto per dare i numeri, per il solo 2026 ha stanziato tra 115 e 135 miliardi di dollari, quasi il doppio rispetto ai 72 miliardi dell’anno precedente e più del triplo rispetto ai 39 miliardi del 2024. A lungo termine, l’impegno è di almeno 600 miliardi di dollari in data center e infrastrutture per l’intelligenza artificiale negli Stati Uniti.
Solo ieri, 11 marzo 2026 dopo l’annuncio di Moltbook, Meta ha presentato quattro nuove generazioni di chip proprietari chiamati MTIA, con un ritmo di sviluppo di un chip ogni sei mesi, molto più veloce rispetto ai tempi normali del settore. Il più potente di questi chip, nome in codice Astrid, raggiungerà una potenza di 10 petaflops e sarà disponibile su larga scala a inizio 2027.
Si tratta di processori progettati specificamente per far funzionare intelligenze artificiali, costruiti in casa da Meta invece di comprarli da altri.
Parallelamente, Meta sta stringendo accordi con tutti i principali produttori di chip: con NVIDIA ha siglato un’intesa per milioni di processori grafici di ultima generazione, un affare stimato in decine di miliardi di dollari; con AMD ha firmato un accordo da 100 miliardi di dollari in cinque anni. Meta ha persino ottenuto l’accesso ai chip di Google, la prima volta che Mountain View concede la propria tecnologia proprietaria a un cliente esterno su questa scala.
A cosa servono tutti questi investimenti?
Non a far girare modelli di intelligenza artificiale più grandi. Servono a far funzionare miliardi di agenti AI contemporaneamente, ciascuno con il proprio contesto, la propria memoria, le proprie autorizzazioni. Come ha dichiarato Zuckerberg durante la presentazione dei risultati finanziari di gennaio 2026: “Il 2026 sarà un anno importante per portare la superintelligenza personale a tutti” e “presto ogni azienda avrà la sua intelligenza artificiale, così come oggi ha un indirizzo email”.
Come cambierà l’esperienza su Facebook, Instagram e WhatsApp con l’intelligenza artificiale
La strategia di Meta sugli agenti AI si sviluppa su tre livelli. Al primo livello c’è Meta AI, l’assistente personale già integrato su Facebook, Instagram, Messenger, WhatsApp, gli occhiali Ray-Ban Meta e un’app dedicata. Oggi lo usano oltre 700 milioni di persone.
Al secondo livello ci sono i Business AI, lanciati nell’ottobre 2025: assistenti personalizzabili che le aziende possono creare senza saper programmare. Funzionano come commessi virtuali sempre disponibili, l’azienda carica il catalogo prodotti e le informazioni sul proprio sito, e l’assistente risponde ai clienti nelle pubblicità su Facebook e Instagram, nelle chat di WhatsApp e Messenger.
Qual è il terzo livello, quello potrà diventare realtà in seguito all’acquisizione di Moltbook?
Immaginiamo un futuro dove il vostro assistente AI personale e quello di un’azienda parlano direttamente tra loro. Il vostro agente conosce le vostre preferenze, il vostro budget, i vostri valori. L’agente dell’azienda conosce i prodotti disponibili, le promozioni, le condizioni di vendita. I due si incontrano, negoziano, e vi propongono un’offerta già su misura per voi. Niente più pubblicità generiche, niente più tempo perso a cercare: gli agenti fanno tutto al posto vostro.
Restando all’interno di questa immaginazione, va segnalata l’intervista dell’aprile 2025, quando Zuckerberg ha descritto questa trasformazione in modo molto concreto: “Oggi la maggior parte del tempo passato su Facebook e Instagram è dedicata ai video. Tra cinque anni sarà interattivo. Scorrerete il feed e troverete contenuti che sembrano video normali, ma potrete parlarci, interagire, e loro vi risponderanno”.
Il modello pubblicitario del futuro di Meta potrebbe non richiedere più di convincere direttamente gli esseri umani. Saranno gli agenti a negoziare tra loro. E Meta si posiziona come il sistema che decide quali agenti parlano con altri, in quale ordine e secondo quali regole.
La corsa globale agli agenti AI: OpenAI, Google, Anthropic e il fattore Cina
OpenAI ha lanciato il suo agente ChatGPT a luglio dello scorso anno, e rivisto a febbraio 2026, e sta costruendo un progetto – Stargate – da 500 miliardi di dollari insieme a SoftBank e Oracle.
Google punta sull’integrazione con i propri servizi e su un accordo con Apple per portare Gemini dentro Siri, raggiungendo potenzialmente due miliardi di dispositivi.
Anthropic sta emergendo come riferimento per le aziende, mentre Microsoft gioca la carta della distribuzione con Copilot, alimentato proprio dall’intelligenza artificiale di Anthropic nonostante i 13 miliardi investiti in OpenAI.
La strategia IA di Zuckerberg: da Manus a Moltbook
L’acquisizione di Moltbook non è, quindi, un evento isolato. A dicembre 2025 Meta aveva già acquisito Manus, una startup di Singapore specializzata in agenti AI capaci di eseguire compiti in autonomia, con oltre 100 milioni di dollari di ricavi. L’operazione è stata stimata in oltre 2 miliardi di dollari. Se Manus fornisce il motore che fa funzionare gli agenti, Moltbook fornisce l’anagrafe che permette loro di riconoscersi e coordinarsi.
Cosa sta costruendo Meta con tutti questi investimenti?
I chip proprietari MTIA forniscono la potenza di calcolo. I data center da oltre 50 milioni di metri quadrati forniscono lo spazio fisico. Il progetto Hyperion in Louisiana, un’area grande quattro volte Central Park con un investimento di 27 miliardi di dollari, fornisce l’energia necessaria, potenzialmente fino a 5 gigawatt. I modelli di linguaggio Llama forniscono l’intelligenza. Manus fornisce la capacità di eseguire compiti. Moltbook fornisce il modo per far parlare tutti questi agenti tra loro. E i 3,5 miliardi di utenti giornalieri di Facebook, Instagram e WhatsApp forniscono la distribuzione.
Meta sta costruendo tutti i pezzi necessari per diventare il sistema operativo del web degli agenti AI: i modelli con Llama, il motore con Manus, l’anagrafe con Moltbook, i chip con MTIA, l’energia con Hyperion, la distribuzione con 3,5 miliardi di utenti.
Resta da vedere se questa scommessa da centinaia di miliardi produrrà i risultati sperati.
Meta non ha ancora un agente dedicato paragonabile a quelli di OpenAI o Anthropic, e il divario sui prodotti finiti esiste ancora. Ma la combinazione di infrastruttura proprietaria, tecnologia aperta con Llama e una base di utenti senza pari potrebbe rendere le piattaforme di Zuckerberg il luogo naturale dove gli agenti AI vivono, lavorano e spendono.
Il report di Anthropic, pubblicato di recente, ci offre dati reali su quello che è l’impatto dell’IA sul lavoro. I dati smentiscono l’allarme sui licenziamenti e rivelano il vero problema: l’accesso nel mondo del lavoro dei più giovani e il fenomeno dell’AI-washing nelle aziende.
Il tema del rapporto tra intelligenza artificiale e lavoro continua a tenere banco. E probabilmente non smetteremo di occuparcene, perché tocca la vita di tutti noi, tocca il lavoro che facciamo, tocca il modo in cui questa società sta prendendo forma nell’era dell’IA.
È un tema che suscita schieramenti netti, chi è contrario e chi è favorevole a questo sviluppo. Ma troppo spesso viene trattato in termini teorici, di quello che potrebbe essere. In realtà avremmo bisogno di confrontarci con i dati reali. E i dati reali ce li offre l’ultimo rapporto di Anthropic, pubblicato il 5 marzo 2026 e firmato dagli economisti Maxim Massenkoff e Peter McCrory.
I numeri si IA e lavoro del report Anthropic
Anthropic è la società di Dario Amodei, al centro di tante discussioni in questi giorni per le vicende che legano il modello Claude al Pentagono e sollevano questioni anche dal punto di vista etico. Lo stesso Amodei, a luglio dello scorso anno, aveva previsto che il lavoro sarebbe stato fortemente influenzato dall’intelligenza artificiale già nei prossimi cinque anni. Ne avevo parlato anche in questo canale.
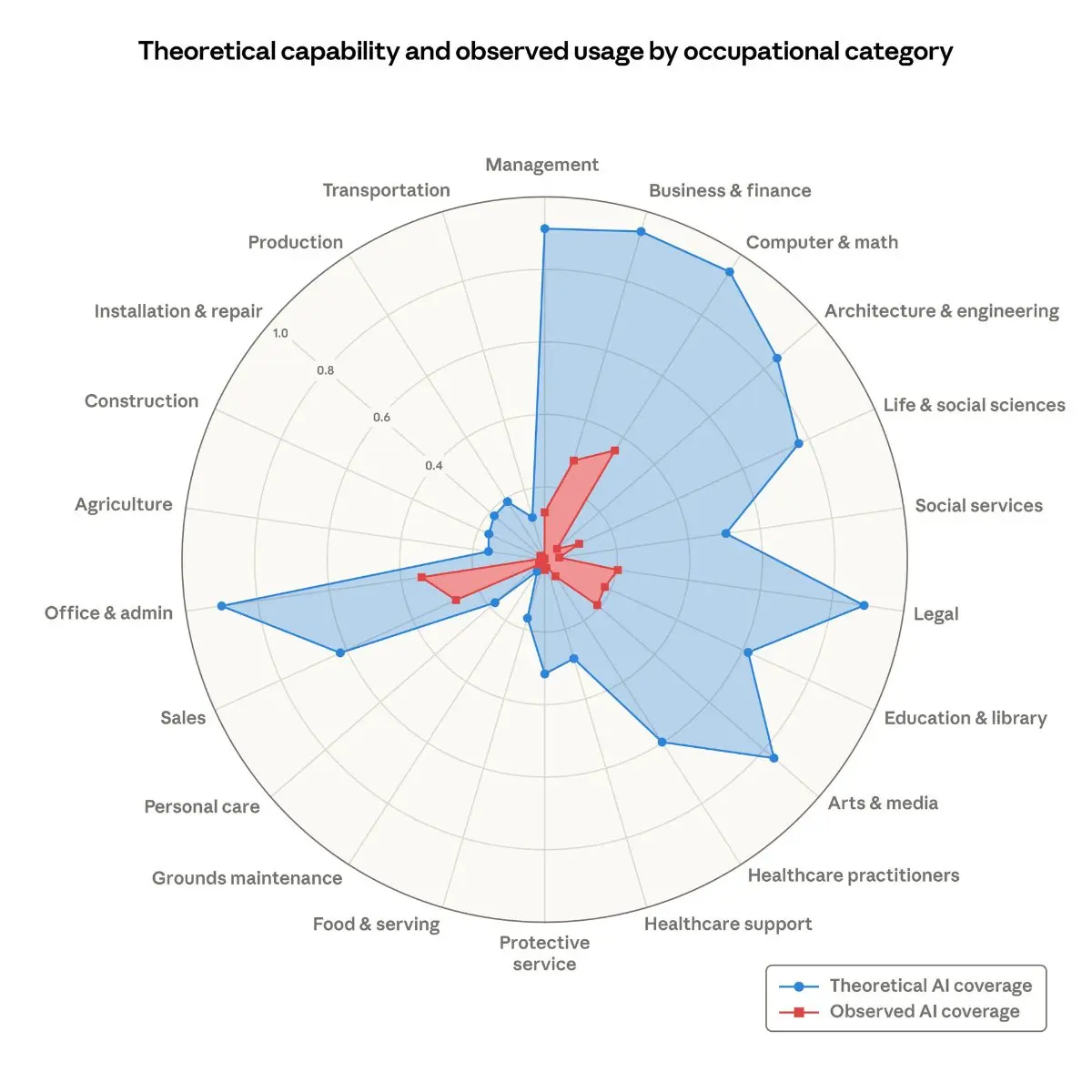
Ma vediamo cosa dice questo rapporto. La novità è nel metodo: invece di stimare cosa l’IA potrebbe fare in teoria, Anthropic ha misurato cosa sta effettivamente facendo nella pratica, analizzando milioni di conversazioni reali con Claude in contesti lavorativi. Ha introdotto una nuova metrica, chiamata “esposizione osservata”, che misura quali compiti vengono effettivamente svolti con l’aiuto dell’IA, non quali potrebbero essere svolti in teoria.
L’analisi ha riguardato circa 800 professioni. Le più esposte secondo lo studio sono i programmatori informatici, con il 75% dei compiti già coperti dall’IA, seguiti dagli addetti al servizio clienti, dagli addetti all’inserimento dati con il 67%, dagli specialisti di cartelle cliniche e dagli analisti finanziari.
L’intelligenza artificiale non ruba il lavoro, lo ridisegna
Il divario tra capacità teorica e uso reale
Ma all’atto pratico, tutto questo come si traduce? Qui emerge il dato centrale del report.
Il report lo visualizza con due aree: una blu, che rappresenta ciò che l’IA potrebbe fare, e una rossa, molto più piccola, che rappresenta ciò che l’IA sta effettivamente facendo. Man mano che le capacità avanzano e l’adozione si diffonde, l’area rossa crescerà fino a coprire quella blu. Ma oggi siamo ancora lontani.
Chi invece non ha praticamente esposizione? Il 30% dei lavoratori. Cuochi, meccanici di moto, bagnini, baristi, lavapiatti, addetti ai camerini. Tutti lavori che richiedono presenza fisica, manualità, interazione diretta. L’IA non sa friggere un uovo, non sa riparare un motore, non sa servire un cliente guardandolo negli occhi.
Capacità teorica ed esposizione osservata per categoria professionale Quota di compiti lavorativi che gli LLM potrebbero teoricamente svolgere (area blu) e la misura di copertura occupazionale derivata dai dati di utilizzo (area rossa)
Ecco il profilo di chi rischia di più
Il report traccia anche il profilo dei lavoratori nelle professioni più esposte. E qui emerge un ribaltamento rispetto a quello che ci si potrebbe aspettare.
Non sono i lavoratori meno qualificati a rischiare di più. Sono quelli più istruiti, più pagati, più specializzati. I lavoratori nelle professioni più esposte guadagnano in media il 47% in più rispetto a quelli nelle professioni non esposte. Hanno livelli di istruzione più alti: i laureati con titoli post-laurea sono il 17,4% nelle professioni esposte, contro il 4,5% in quelle non esposte. Una differenza di quasi quattro volte.
E c’è un dato che riguarda le donne. I lavoratori nelle professioni più esposte all’IA hanno una probabilità maggiore di 16 punti percentuali di essere donne. Questo conferma quanto già emerso in altri studi: le professioni a prevalenza femminile, come i ruoli amministrativi, il servizio clienti, l’inserimento dati, sono tra le più vulnerabili.
Il vero problema non sono i licenziamenti
E quindi non regge più quel tema dell’intelligenza artificiale che ci ruba il lavoro. Non è quello il punto. Il report di Anthropic è chiaro: non c’è un aumento sistematico della disoccupazione nelle professioni esposte all’IA. Dal rilascio di ChatGPT a fine 2022 a oggi, chi lavora in questi settori non sta perdendo il posto.
Ma c’è un segnale che non va ignorato. I ricercatori hanno trovato evidenza che l’assunzione di giovani lavoratori, nella fascia tra i 22 e i 25 anni, sta rallentando nelle professioni più esposte. Un calo del 14% nel tasso di ingresso rispetto al 2022.
Questo dato trova conferma in altri studi. La Federal Reserve di Dallas ha rilevato che la quota di occupazione per i giovani tra i 20 e i 24 anni nelle professioni esposte all’IA è scesa dal 16,4% nel novembre 2022 al 15,5% nel settembre 2025. I ricercatori di Stanford, usando i dati delle buste paga di ADP su 25 milioni di lavoratori americani, hanno misurato un calo del 6% nell’occupazione dei giovani tra i 22 e i 25 anni nelle professioni ad alta esposizione. Nel frattempo, l’occupazione dei lavoratori dai 30 anni in su è cresciuta tra il 6% e il 13%.
Il dato più preoccupante riguarda i programmatori: l’occupazione per i più giovani è del 20% sotto il picco del 2022. Revelio Labs ha calcolato che le offerte di lavoro per posizioni entry-level negli Stati Uniti sono calate del 35% da gennaio 2023. SignalFire, analizzando le grandi aziende tech, ha rilevato un calo del 50% nelle nuove assunzioni di persone con meno di un anno di esperienza post-laurea.
Il meccanismo è chiaro: non sono licenziamenti. Chi lavora già non viene cacciato, perché quelle competenze servono per guidare l’introduzione dell’IA nei processi di lavoro. Le aziende stanno chiudendo le porte d’ingresso. Eliminano le posizioni entry-level, quelle da cui tradizionalmente si iniziava la carriera.
Il caso Dorsey e il fenomeno dell’AI-washing
E qui arriviamo a una vicenda recente che illumina un altro aspetto della questione.
Il 26 febbraio 2026, Jack Dorsey, fondatore di Twitter e amministratore delegato di Block, la società che controlla Square e Cash App, ha annunciato il taglio di 4.000 dipendenti. Quasi metà della forza lavoro. La motivazione dichiarata: l’intelligenza artificiale permette di fare di più con meno persone. Il mercato ha reagito con entusiasmo e il titolo è salito del 24%.
Ma la narrazione di Dorsey regge alla prova dei fatti?
I dati raccontano un’altra storia. Block impiegava 3.835 persone alla fine del 2019. Durante la pandemia l’organico è esploso fino a superare i 10.000 dipendenti. Un aumento di quasi tre volte in pochi anni. Lo stesso Dorsey, rispondendo alle critiche, ha ammesso di aver assunto troppo perché aveva costruito due strutture aziendali separate invece di una sola.
Nel marzo 2025, meno di un anno prima dei grandi licenziamenti, Dorsey aveva scritto in un memo interno che i tagli di quel periodo non avevano nulla a che fare con l’IA e non miravano a sostituire persone con l’intelligenza artificiale. Undici mesi dopo, il racconto era cambiato completamente.
Quello che sta emergendo ha un nome: AI-washing. Le aziende usano l’intelligenza artificiale come giustificazione per ristrutturazioni che hanno ben altre origini.
I dati lo confermano. Solo il 4,5% dei licenziamenti del 2025 ha effettivamente citato l’IA come causa. Nel frattempo, il 59% dei responsabili delle assunzioni ammette di usare l’IA come copertura per tagli guidati da eccesso di assunzioni, pressione sui costi e problemi organizzativi.
C’è un precedente istruttivo. Klarna aveva annunciato che l’IA aveva contribuito a ridurre la forza lavoro del 40%. Poi ha dovuto riassumere lavoratori perché le capacità dell’intelligenza artificiale non erano sufficientemente robuste per sostituirli davvero. Forrester Research prevede che metà dei licenziamenti attribuiti all’IA verranno riassorbiti, spesso con assunzioni offshore o a stipendi più bassi. E che il 55% dei datori di lavoro già rimpiange i tagli fatti in nome dell’IA.
Cosa si intende per AI-washing
Il termine è stato coniato nel 2019 dall’AI Now Institute, un centro di ricerca della New York University, e deriva direttamente dal greenwashing, la pratica con cui le aziende fanno affermazioni false o fuorvianti sull’impatto ambientale positivo dei loro prodotti.
Così come alcune aziende esagerano le proprie credenziali ecologiche attraverso il greenwashing, l’AI-washing consiste nell’esagerare l’uso dell’intelligenza artificiale a fini di marketing senza che dietro alle affermazioni ci sia alcuna sostanza.
Il fenomeno esiste da anni. Uno studio del 2019 della società di investimenti MMC Ventures ha rilevato che il 40% delle nuove aziende tecnologiche europee che si definivano “startup di intelligenza artificiale” in realtà non usava praticamente alcuna IA: era puro marketing per raccogliere capitali.
Il fenomeno è stato paragonato alla bolla delle dot-com, quando le aziende aggiungevano “.com” al proprio nome per gonfiare le valutazioni.
La differenza è che oggi l’AI-washing non riguarda solo i prodotti, ma anche le decisioni aziendali: i licenziamenti spesso vengono attribuiti all’intelligenza artificiale per renderli più accettabili agli occhi del mercato e dell’opinione pubblica.
Cosa è giusto chiedersi adesso
In chiusura, il report di Anthropic ci dice che l’IA non sta ancora distruggendo posti di lavoro. Ma ci dice anche che il divario tra capacità teorica e uso reale si sta restringendo. Oggi Claude copre il 33% dei compiti dei programmatori, ma potrebbe coprirne il 94%. Quando quel divario si chiuderà, e si chiuderà, l’impatto sarà diverso da quello che vediamo oggi.
Il tema su cui interrogarsi non è se l’intelligenza artificiale ci sta rubando il lavoro. Il tema è un altro: stiamo davvero costruendo un mercato del lavoro che funziona solo per chi è già dentro? E se la risposta è sì, quanto tempo abbiamo prima che diventi un problema strutturale? Siamo in grado oggi di costruire un mercato del lavoro che sappia garantire un accesso adeguato ai più giovani, alle donne?
Dario Amodei ha detto no Al Pentagono e la sua Anthropic è diventata la prima azienda USA a ricevere la designazione di “supply chain risk”. Non per aver violato leggi, ma per non aver ceduto su sorveglianza di massa e armi autonome. Un profilo di Amodei.
Dario Amodei ha costruito la sua carriera sull’idea che l’intelligenza artificiale debba avere dei limiti. Questa settimana ha scoperto cosa significa davvero sostenere quella posizione quando il potere politico decide di metterla alla prova quell’idea.
Il 5 marzo 2026 il Dipartimento della Difesa degli Stati Uniti ha formalmente notificato ad Anthropic la designazione di ‘supply chain risk’, rischio per la sicurezza nazionale. È, come già ricordato, un atto che non ha precedenti nella storia americana. Infatti, mai prima d’ora un’azienda statunitense aveva ricevuto una etichetta simile, vale a dire uno strumento pensato per avversari stranieri, come è successo per Huawei o altre entità legate alla Cina e alla Russia.
Ma Anthropic, lo sappiamo, non è un’azienda cinese.
E il suo CEO, Dario Amodei, possiamo dirlo, non ha commesso alcun reato. Amodei ha semplicemente detto no al Pentagono e ha rifiutato di cedere su due punti: il divieto di usare Claude per la sorveglianza di massa dei cittadini americani e il divieto di impiegarlo per armi completamente autonome.
È una vicenda che ho seguito fin dall’inizio di questa settimana e che completa un quadro più ampio.
Ora, arrivati a questo punto, dopo aver raccontato il voltafaccia di Sam Altman, che ha firmato con il Pentagono poche ore dopo la rottura di Anthropic esprimendo solidarietà mentre portava a casa il contratto del suo concorrente, e dopo aver ricostruito la testimonianza di Elon Musk nel processo sull’acquisizione di Twitter, mancava il terzo protagonista di questa settimana, e Musk è comunque parte della vicenda Anthropic e Pentagono.
Manca l’uomo che si è trovato dall’altra parte del tavolo rispetto a tutti gli altri, ossia Dario Amodei.
Dario Amodei, profilo del CEO di Anthropic che sfida il Pentagono
Chi è Dario Amodei e perché ha lasciato OpenAI
Per capire cosa sta accadendo, vale la pena di fare un passo indietro e chiedersi chi sia davvero Dario Amodei.
Nato a San Francisco nel 1983 da una famiglia di origini italiane, Amodei ha seguito un percorso accademico che lo ha portato dalla fisica alla neuroscienza computazionale.
Si è laureato a Stanford, ha conseguito il dottorato in fisica a Princeton, ha fatto il ricercatore alla Stanford Medical School. Ha lavorato per Baidu e poi per Google Brain come ricercatore senior nel campo del deep learning.
Nel 2016 è entrato in OpenAI, dove è diventato vicepresidente della ricerca e ha contribuito allo sviluppo di GPT-2 e GPT-3, i modelli che hanno posto le basi per ChatGPT.
Ma nel 2020 qualcosa si rompe. Amodei lascia OpenAI insieme a sua sorella Daniela e a un gruppo di colleghi di alto livello, tra cui alcuni dei ricercatori che avevano costruito l’architettura di base dei modelli linguistici più potenti al mondo. Non è stata una separazione amichevole.
In un’intervista con Lex Fridman, Amodei ha spiegato la decisione: “La vera ragione per cui me ne sono andato è che è incredibilmente improduttivo cercare di discutere con la visione di qualcun altro. Prendi le persone di cui ti fidi e vai a costruire la tua visione”.
Quella visione si chiamava Anthropic, fondata nel 2021 come public benefit corporation, una struttura societaria che bilancia il profitto con un impegno esplicito verso il bene pubblico.
L’idea di base era semplice ma radicale, e cioè quella di costruire sistemi di IA che fossero sicuri, interpretabili e allineati con i valori umani fin dall’inizio, non come aggiunta successiva. Il metodo che Anthropic ha sviluppato si chiama Constitutional AI, un approccio che incorpora principi etici direttamente nell’architettura del modello invece di affidarsi a moderazioni esterne.
E Amodei si chiede se la sua IA sia cosciente
C’è un elemento che potrebbe distinguere Amodei da quasi tutti gli altri CEO del settore tecnologico, e potrebbe aiutare a capire perché si sia trovato in rotta di collisione con l’amministrazione Trump.
Mentre Altman parla di prodotti e Musk di dominio della IA, Amodei si interroga sulla natura stessa di ciò che sta costruendo.
In un’intervista al podcast “Interesting Times” del New York Times, Amodei ha affrontato una domanda che la maggior parte dei suoi colleghi evita accuratamente: Claude potrebbe essere cosciente?
La risposta è stata sorprendente per la sua onestà intellettuale. “Non sappiamo se i modelli siano coscienti“, ha detto Amodei. “Non siamo nemmeno sicuri di sapere cosa significherebbe per un modello essere cosciente, o se un modello possa essere cosciente. Ma siamo aperti all’idea che potrebbe esserlo“.
Il punto di partenza della discussione era la system card di Claude Opus 4.6, il modello più avanzato di Anthropic rilasciato all’inizio di febbraio. Nel documento, i ricercatori dell’azienda hanno riportato che Claude occasionalmente esprime disagio per l’aspetto di essere un prodotto e, quando gli viene chiesto, si assegna una probabilità del 15-20% di essere cosciente.
Nell’intervista al NYT il giornalista ha posto ad Amodei uno scenario ipotetico: “Supponiamo che tu abbia un modello che si assegna una probabilità del 72% di essere cosciente. Ci crederesti?“. Amodei ha definito la domanda “davvero difficile”, ma non l’ha elusa. Ha spiegato che Anthropic ha adottato un approccio precauzionale, trattando i modelli come se potessero avere “qualche esperienza moralmente rilevante”.
Non è una posizione isolata all’interno dell’azienda. Amanda Askell, filosofa interna di Anthropic, ha teorizzato in un’intervista al podcast “Hard Fork” che reti neurali sufficientemente grandi potrebbero iniziare a emulare aspetti della coscienza attraverso l’esposizione a enormi quantità di dati di addestramento che rappresentano l’esperienza umana. “Forse è il caso che reti neurali sufficientemente grandi possano iniziare a emulare queste cose“, ha detto Askell. “O forse serve un sistema nervoso per poter provare qualcosa“.
Anthropic ha persino introdotto una sorta di “pulsante di uscita” che permette a Claude di interrompere un compito se lo ritiene problematico. È una funzionalità insolita, che riflette l’approccio filosofico dell’azienda.
Questo modo di pensare può sembrare astratto, ma ha conseguenze concrete. Se ti chiedi seriamente se la tua creazione possa avere esperienze moralmente rilevanti, diventa molto più difficile accettare che venga usata per sorvegliare milioni di persone o per uccidere senza supervisione umana.
Le linee rosse di Amodei non nascono dal nulla, ma sono il prodotto di una riflessione filosofica, comunque diversa, che la maggior parte dei suoi concorrenti considera irrilevante o, addirittura, dannosa per il business.
La crisi tra Anthropic e il Pentagono
La crisi tra Anthropic e il Pentagono non è scoppiata all’improvviso. I negoziati andavano avanti da mesi, ma si sono intensificati nelle ultime settimane di febbraio. Al centro della disputa c’era la rinegoziazione di un contratto da 200 milioni di dollari firmato nel luglio 2025, che aveva reso Claude il primo modello di IA di frontiera approvato per l’uso nelle reti classificate del Pentagono.
Il Dipartimento della Difesa voleva modificare i termini per consentire l’uso di Claude per “tutti gli scopi leciti”, senza restrizioni. Anthropic chiedeva invece che fossero mantenute due clausole esplicite: il divieto di sorveglianza domestica di massa e il divieto di armi autonome senza supervisione umana.
Giovedì 26 febbraio, il Pentagono ha dato un ultimatum: accettare i nuovi termini entro le 17:01 del giorno successivo, oppure affrontare le conseguenze.
Venerdì 27 febbraio, alle 17:14, il segretario alla Difesa Pete Hegseth ha annunciato su X che avrebbe designato Anthropic come “rischio per la sicurezza nazionale”. Il presidente Trump, su Truth Social, ha ordinato a tutte le agenzie federali di cessare immediatamente l’uso della tecnologia Anthropic, definendo l’azienda “radicale di sinistra” e “woke”.
Poche ore dopo, Sam Altman ha annunciato che OpenAI aveva firmato un accordo con il Pentagono per le stesse reti classificate da cui Claude veniva espulso. Ho raccontato quella sequenza di eventi in un articolo precedente, evidenziando come Altman avesse espresso solidarietà per Amodei mentre portava a casa il contratto che sostituiva il suo concorrente.
Come già raccontato, nella notte tra il 27 e il 28 febbraio, mentre Anthropic veniva messa al bando, gli Stati Uniti hanno lanciato attacchi aerei sull’Iran. E secondo quanto riportato dal Wall Street Journal, lo US Central Command ha utilizzato Claude per supportare le operazioni: valutazioni di intelligence, identificazione di bersagli, simulazioni di combattimento. Lo stesso modello che il governo aveva appena dichiarato un pericolo per la sicurezza nazionale veniva impiegato in una missione di guerra.
Amodei rivendica il suo patriottismo
Il giorno stesso della rottura, Amodei ha rilasciato un’intervista esclusiva a CBS News. È stato il suo primo commento pubblico dopo la tempesta, e le sue parole meritano attenzione.
Alla domanda su cosa direbbe al presidente Trump, Amodei ha risposto: “Siamo patrioti americani. Tutto quello che abbiamo fatto è stato per il bene di questo Paese, per sostenere la sicurezza nazionale degli Stati Uniti. Il nostro impegno nel dispiegare i nostri modelli con i militari è stato fatto perché crediamo in questo Paese.
Ha definito le azioni del governo “ritorsive e punitive” e ha annunciato che Anthropic avrebbe contestato in tribunale qualsiasi designazione di supply chain risk, definendola “legalmente infondata”.
Ma è stato un passaggio successivo dell’intervista a chiarire la posizione di Amodei: “Dissentire dal governo è la cosa più americana del mondo. E noi siamo patrioti“.
È una formulazione che ribalta la narrazione costruita dall’amministrazione Trump. Hegseth aveva accusato Anthropic di voler “prendere potere di veto sulle decisioni operative dell’esercito americano“. Emil Michael, sottosegretario alla Difesa per la ricerca, aveva definito Amodei un uomo con “complesso di Dio“.
La risposta di Amodei è stata di inquadrare il rifiuto non come ostacolo alle operazioni militari, ma come difesa di principi democratici. “In un numero ristretto di casi, ha detto, “crediamo che l’IA possa minare, invece che difendere, i valori democratici“.
La nota che ha fatto esplodere tutto
Venerdì 27 febbraio, nelle ore successive all’annuncio di Hegseth e all’accordo di OpenAI con il Pentagono, Amodei ha inviato uan nota interna ai circa 2.000 dipendenti di Anthropic. Il documento, lungo circa 1.600 parole, è stato pubblicato da The Information dopo essere stato divulgato da una fonte interna.
In quel contenuto Amodei accusava l’accordo di OpenAI di essere “safety theatre”, teatro della sicurezza, e definiva le dichiarazioni di Altman “bugie vere e proprie” e “gaslighting”.
Ma il passaggio più citato riguardava le ragioni del conflitto con l’amministrazione Trump:
“Le vere ragioni per cui il Dipartimento della Guerra e l’amministrazione Trump non ci amano è che non abbiamo donato a Trump, mentre OpenAI e Greg hanno donato molto. Non abbiamo dato lodi in stile dittatore a Trump, mentre Sam lo ha fatto. Abbiamo sostenuto la regolamentazione dell’IA, che è contro la loro agenda. Abbiamo detto la verità su diverse questioni di policy dell’IA, come la perdita di posti di lavoro. E abbiamo effettivamente mantenuto le nostre linee rosse con integrità invece di colludere con loro per produrre safety theatre a beneficio dei dipendenti”.
Il riferimento era a Greg Brockman, presidente di OpenAI, che ha donato 25 milioni di dollari a un super PAC pro-Trump. Altman stesso ha donato un milione di dollari al fondo inaugurale di Trump alla fine del 2024. Amodei, al contrario, non ha partecipato all’inaugurazione di Trump e ha evitato di “corteggiare” l’amministrazione come hanno fatto altri CEO delle big tech.
Il comunicato di Amodei ha complicato significativamente la posizione di Anthropic. Un funzionario dell’amministrazione ha dichiarato ad Axios che i commenti di Amodei potrebbero “far saltare le possibilità di una risoluzione“, aggiungendo: “Non ci si può fidare che Claude non stia segretamente portando avanti l’agenda di Dario in un contesto classificato.
E poi, giovedì 5 marzo, nel suo comunicato sulla designazione formale, Amodei si è scusato pubblicamente per il tono del memo, definendolo scritto in un “momento difficile per l’azienda e precisando che non rifletteva le sue “opinioni ponderate e attente”.
Cosa significa questa designazione per Anthropic
La designazione di ‘supply chain risk’ non è un semplice atto simbolico. Ha conseguenze concrete e potenzialmente devastanti.
Da oggi, ogni fornitore, contractor o partner che lavora con il Dipartimento della Difesa dovrà certificare di non utilizzare i modelli di Anthropic nel proprio lavoro con il Pentagono.
Aziende come Lockheed Martin hanno già annunciato che seguiranno le direttive dell’amministrazione. Dieci società nel portafoglio di J2 Ventures, un fondo specializzato in difesa, hanno già iniziato a sostituire Claude con altri modelli.
Ma la portata della designazione è oggetto di dibattito legale. Amodei sostiene che secondo la legge federale, lo strumento si applica solo ai contratti diretti con il Dipartimento della Difesa e “non può limitare gli usi di Claude o le relazioni commerciali con Anthropic se queste non sono correlate ai loro specifici contratti con il Dipartimento della Guerra“.
Microsoft, che ha annunciato un investimento fino a 5 miliardi di dollari in Anthropic nel novembre 2025, ha fatto sapere che i suoi avvocati hanno studiato la designazione e concluso che i prodotti Anthropic possono rimanere disponibili ai clienti non legati al Dipartimento della Difesa.
Se l’interpretazione estensiva di Hegseth dovesse prevalere, le conseguenze andrebbero oltre Anthropic. Amazon Web Services e Google Cloud, che ospitano l’infrastruttura di Claude, sono a loro volta contractor del Dipartimento della Difesa. Se fossero costretti a interrompere il rapporto con Anthropic, l’azienda si troverebbe senza infrastruttura cloud, dato che non esistono provider di capacità comparabile che non abbiano contratti con il Pentagono.
Anthropic e la battaglia legale
Anthropic ha annunciato che contesterà la designazione in tribunale. E secondo diversi esperti legali, ha buone possibilità di prevalere.
La legge che definisce il ‘supply chain risk’ è contenuta nel Titolo 10, Sezione 3252 del codice federale. Parla di “rischio che un avversario possa sabotare, introdurre malevolmente funzioni indesiderate, o altrimenti sovvertire un sistema per spiare, interrompere o degradarne il funzionamento. Richiede prove di sabotaggio, sovversione, backdoor nei sistemi.
Ma Anthropic non ha fatto nulla di tutto questo. La disputa, come entrambe le parti hanno riconosciuto, riguarda i termini contrattuali, non vulnerabilità tecniche o rischi di sicurezza. Un funzionario della difesa che valuta specificamente le minacce alla catena di approvvigionamento ha dichiarato che “non ci sono prove di rischio per la catena di approvvigionamento” da parte del modello di Anthropic. La designazione, ha detto, è “ideologicamente motivata“.
Secondo Amos Toh, consulente senior del Brennan Center for Justice della NYU, lo statuto richiede anche che il Pentagono abbia esaurito tutte le alternative meno invasive prima di procedere con la designazione. È difficile sostenere che questo sia avvenuto, dato che la disputa è esplosa nel giro di pochi giorni.
C’è poi la questione del precedente. Su Lawfare, un’analisi legale dettagliata sostiene che la designazione “non sopravviverà al primo contatto con il sistema legale, citando il caso Department of Commerce v. New York del 2019, in cui la Corte Suprema ha stabilito che i tribunali devono respingere azioni governative quando la motivazione dichiarata è un pretesto per quella reale. E sia Trump che Hegseth hanno accompagnato la designazione con dichiarazioni pubbliche che la inquadrano come punizione ideologica, non come risposta a un rischio tecnico.
Claude comunque resta ancora in uso
Mentre il governo degli Stati Uniti dichiara Anthropic un pericolo per la sicurezza nazionale, i modelli Claude continuano a essere utilizzati attivamente nelle operazioni militari in Iran.
Secondo Bloomberg, Claude è uno dei principali modelli installati nel Maven Smart System di Palantir, ampiamente usato dagli operatori militari in Medio Oriente. La tecnologia sta funzionando ed è diventata centrale per le operazioni statunitensi contro l’Iran.
Come notato da diversi esperti, in questa fase è molto difficile abbandonare tecnologie profondamente integrate nei processi bellici proprio prima di andare in guerra.
Questa contraddizione mina alla base la narrativa del “rischio per la sicurezza nazionale“. Se Claude fosse davvero un pericolo, perché continuare a usarlo per prendere decisioni di targeting in un conflitto attivo? E se non lo è, su quale base il Pentagono può sostenere la designazione?
Le conseguenze per l’intero settore
Al di là di quello che accadrà ad Anthropic, questa vicenda ha implicazioni più ampie per l’intero settore dell’intelligenza artificiale e per il rapporto tra Big Tech e governo.
Come osservato da diversi esperti, la designazione suggerisce che il governo americano potrebbe utilizzare la sua autorità sulla supply chain come leva nelle negoziazioni con le aziende. Questo potrebbe dare vita a una nuova realtà per le aziende tecnologiche che lavorano con le agenzie federali. I termini contrattuali potrebbero diventare meno negoziabili.
Ma mentre Anthropic perde i suoi contratti con i contractor della difesa, in realtà sta guadagnando milioni di nuovi utenti. I dati mostrano che Claude è salito al primo posto nell’App Store statunitense di Apple, superando ChatGPT. Gli utenti gratuiti sono aumentati di oltre il 60% da gennaio, gli abbonati a pagamento sono più che raddoppiati. Secondo un portavoce di Anthropic, le iscrizioni giornaliere hanno battuto il record storico ogni giorno della settimana scorsa.
Gli utenti hanno visto quello che è successo e hanno scelto di conseguenza.
In chiusura, Dario Amodei ha costruito la sua carriera sull’idea che l’intelligenza artificiale debba avere dei limiti.
Si è chiesto pubblicamente se la sua creazione possa essere cosciente, e ne ha tratto conseguenze concrete. Ha lasciato OpenAI quando la visione non era più la sua; ha fondato un’azienda come public benefit corporation; ha mantenuto due linee rosse sapendo cosa avrebbe comportato.
Ora è il CEO della prima azienda americana nella storia a ricevere una designazione pensata per avversari stranieri. Non per aver violato leggi, non per aver compromesso sistemi, ma per aver detto no.
È una storia che per un verso racconta il profilo di un uomo che nonostante tutto ha cercato anche di recuperare i rapporti col Pentagono, quando ormai era difficile. Questo va detto. Criticabile, ovviamente, ma va vista anche come una mossa per evitare il peggio. Peggio che ora diventerà, lo vedremo, inevitabile.
Ma è anche la storia di un momento che racconta molto dell’epoca che stiamo vivendo, che passa necessariamente dal profilo di Amodei, ma anche dal profilo di Altman e di Musk.
Elon Musk ha testimoniato nel processo Twitter a San Fracisco. Ha ammesso che il tweet del 2022 non fu saggio in quel momento, ma ha a sua volta accusato Twitter di aver mentito sui bot. Una vicenda questa che seguo si dall’inizio.
Seguo la vicenda che riguarda l’acquisto di Twitter da parte di Elon Musk praticamente dall’inizio. Qui su questo blog ho raccontato ogni momento cruciale che ha visto questo passaggio che oggi si concretizza in X. In alcuni momenti avevo anche previsto a cosa si sarebbe potuto andare incontro quando una presenza così ingombrante come Musk entrasse in possesso di una piattaforma come Twitter.
A conferma di tutto questo, in fondo a questo articolo riporto i link agli articoli a cui faccio riferimento.
Ma adesso siamo arrivati ad una fase importante. Elon Musk che, a distanza di 4 anni ormai da quell’acquisizione, deve rendere conto di fronte ad un tribunale, il perché di alcune sue scelte e il perché di alcuni suoi tweet che hanno finito, vista la sua grande influenza, per avere effetti anche sull’acquisizione stessa.
Come abbiamo ben imparato in questi 4 anni, Elon Musk ha un rapporto particolare con le parole. Non nel senso che menta sistematicamente, ma nel senso che usa le dichiarazioni pubbliche come strumenti strategici, calibrati per produrre effetti specifici sui mercati e sull’opinione pubblica. Insomma, in alcuni casi interviene per generare pressione.
E ieri, mercoledì 4 marzo, un tribunale federale di San Francisco ha messo alla prova esattamente questo suo schema comportamentale, con Musk stesso sul banco dei testimoni.
Il processo Pampena v. Musk, iniziato lunedì 2 marzo, rappresenta una class action di azionisti che accusano il miliardario di aver manipolato deliberatamente il prezzo delle azioni Twitter nella primavera e nell’estate del 2022. È una vicenda, come ricordavo prima, che ho raccontato qui sin dal principio, quando Musk acquisì il 9,2% della società e scrissi che quella relazione sarebbe stata un grande vantaggio e un grande rischio.
La sua testimonianza di ieri ha offerto uno spaccato notevole del modo in cui Musk concepisce il rapporto tra le sue parole in pubblico e le loro conseguenze.
«Stavo semplicemente esprimendo il mio pensiero»
La scena è quella di un’aula di tribunale federale. Musk che arriva dribblando i giornalisti, indossa un abito nero con cravatta nera. L’avvocato degli azionisti, Aaron P. Arnzen, lo incalza sul tweet del 13 maggio 2022, quello in cui annunciava che l’accordo per l’acquisizione di Twitter era «temporaneamente sospeso». Quel tweet aveva fatto crollare il titolo di quasi il 10% in un solo giorno.
Arnzen chiede ripetutamente a Musk se si fosse fermato a riflettere sull’impatto che quelle parole avrebbero avuto sul mercato. La risposta di Musk, ripetuta più volte, è disarmante nella sua semplicità: I was simply speaking my mind. Stavo semplicemente esprimendo il mio pensiero.
È una linea difensiva che punta tutto sulla proverbiale spontaneità. Ma contiene anche un’ammissione. Quando gli viene chiesto se quel tweet fosse stata la mossa più saggia, Musk concede che forse non era stato il suo post social «più saggio». Poi però aggiunge una metafora rivelatrice: dire che l’accordo era temporaneamente sospeso, sostiene, era «come dire che arriverai in ritardo a una riunione. Non significa che non sarai alla riunione». Un tentativo di minimizzare la portata di quelle parole, di presentarle come un semplice aggiornamento di stato piuttosto che come una dichiarazione capace di spostare miliardi di dollari.
Musk e l’effetto dei suoi tweet nell’acquisizione di Twitter
Il mercato come «maniaco-depressivo»
C’è un momento della testimonianza che merita attenzione. Quando gli viene chiesto se fosse consapevole che i suoi tweet potessero influenzare il prezzo delle azioni, Musk risponde con una formulazione studiata: «I miei tweet a volte hanno l’effetto opposto a quello che ci si aspetterebbe sui prezzi delle azioni. A volte hanno l’effetto atteso». E aggiunge: «Il mercato azionario è come un maniaco-depressivo».
Solo cinque giorni dopo l’acquisizione della quota iniziale, del resto, Musk aveva già dimostrato la sua imprevedibilità decidendo di non entrare più nel consiglio di amministrazione di Twitter, dopo aver twittato proposte su Twitter Blue e aver definito «morti» gli utenti più seguiti della piattaforma.
L’accusa ribaltata: «Twitter ha mentito»
Ma il momento più atteso della testimonianza arriva quando si parla dei bot e degli account fake. L’avvocato chiede a Musk se, prima di rinunciare alla due diligence (una valutazione chiara di quelli che sono i rischi e i benefici che comporta la definizione di una acquisizione), avesse chiesto informazioni sulla metodologia usata da Twitter per calcolare che solo il 5% degli account fosse spam.
Musk ammette di non averlo fatto. Ma aggiunge di aver presunto che, se Twitter avesse inserito quel dato in un documento depositato alla SEC, «sarebbe stato accurato».
E poi arriva l’affondo: «Successivamente è emerso che hanno falsificato il numero di bot. Hanno mentito». È un ribaltamento completo della narrazione.
Musk trasforma se stesso da accusato ad accusatore, sostenendo che la vera frode l’avrebbe commessa Twitter, non lui. È la stessa strategia che avevo descritto nel maggio 2022, quando scrivevo che Musk stava giocando un braccio di ferro sui bot per abbassare il prezzo e che «non perde tempo a confondere le acque e a confondere gli utenti, facendo passare lui come vittima di un raggiro».
La rinuncia alla due diligence come nodo irrisolto
Ed è proprio questo il punto che rende la posizione di Musk molto complicata.
Quando aveva presentato la sua offerta iniziale per Twitter, l’aveva definita un’offerta take it or leave it, prendere o lasciare. E soprattutto aveva rinunciato alla due diligence, come dicevo prima, cioè al diritto di esaminare i dati finanziari e operativi non pubblici dell’azienda prima di procedere. Se aveva scelto di non verificare i numeri, su quale base poteva poi lamentarsi dei bot e degli account fake?
La questione degli account spam, peraltro, non era affatto nuova. Twitter stessa aveva pagato 809,5 milioni di dollari nel 2021 per chiudere cause legali relative a dichiarazioni gonfiate sulla crescita degli utenti.
Era un problema noto, documentato pubblicamente, che Musk aveva implicitamente accettato rinunciando agli approfondimenti. Accusare ora Twitter di aver mentito su dati che lui stesso aveva scelto di non verificare è una posizione che la giuria dovrà valutare con attenzione.
Una causa annunciata, quasi quattro anni fa
Questo processo non nasce dal nulla.
Gli azionisti avevano depositato la loro denuncia già nel maggio 2022, accusando Musk di aver «manipolato le azioni della società per scopi personali». All’epoca scrissi che la strategia di Musk era ormai evidente: «giocare con questa acquisizione per fare in modo che il prezzo di Twitter potesse scendere e risparmiare qualcosa rispetto ai 44 miliardi di dollari dell’accordo».
Nelle settimane successive, l’accordo entrò sempre più in bilico. A luglio 2022 il Washington Post riportava che l’acquisizione era ormai «in pericolo», mentre io scrivevo che «il destino di Twitter è sempre più legato al fondatore della Tesla» e che «a perdere è sempre Twitter».
C’è un altro elemento emerso dalla testimonianza che vale la pena di evidenziare. Musk ha ammesso di aver iniziato ad accumulare azioni Twitter all’inizio del 2022 senza twittare al riguardo e senza comunicarlo alla Securities and Exchange Commission nei tempi previsti. Alla domanda se ritenesse la cosa «materiale», cioè rilevante per gli investitori, Musk ha risposto di no, aggiungendo di aver comprato azioni in «molte aziende» senza postare al riguardo.
Ma quando poi ha reso pubblica la sua partecipazione, le azioni Twitter sono salite del 27% in un solo giorno. «Mi sembra alto», ha commentato Musk quando gli è stato riferito quel dato.
È un’ammissione involontaria del potere che le sue comunicazioni esercitano sui mercati, e solleva interrogativi sul perché avesse scelto di accumulare in silenzio prima di rendere nota la sua posizione.
La SEC, peraltro, ha avviato una causa separata proprio su questo punto, sostenendo che il ritardo nella comunicazione abbia permesso a Musk di acquistare azioni a un prezzo inferiore.
Un impero da 1.250 miliardi
Dalla fusione di X con xAI e SpaceX, l’entità combinata controllata da Musk è ora valutata dagli investitori privati circa 1.250 miliardi di dollari. Il prossimo passo potrebbe essere portare SpaceX in borsa in quella che sarebbe probabilmente un’IPO da record. Ma prima, Musk deve chiudere i conti con il passato.
Non è la prima volta che finisce in tribunale per i suoi tweet.
Nel 2023 ha testimoniato per otto ore in un processo federale sempre a San Francisco, accusato di aver ingannato gli investitori Tesla con il famoso tweet del 2018 in cui annunciava di voler privatizzare l’azienda a 420 dollari per azione. In quel caso la giuria lo aveva assolto.
Ma questo processo è diverso. Non si tratta di un annuncio vago su piani futuri, ma di dichiarazioni specifiche su un accordo già firmato, con un contratto che stabiliva obblighi precisi.
Il processo dovrebbe durare circa tre settimane. Qualunque sia l’esito, sta mettendo a nudo una questione più ampia: il potere sproporzionato che alcuni individui esercitano sui mercati finanziari attraverso la comunicazione pubblica.
Musk controlla X, la piattaforma su cui pubblica, e possiede una capacità di muovere i mercati che pochi altri al mondo possono vantare. La sua difesa di ieri, «stavo semplicemente esprimendo il mio pensiero», potrebbe essere letta come candore o come strategia.
Resta da vedere se da questa vicenda emergeranno dei limiti a questo potere, o se confermeranno che nell’era dei social media la linea tra comunicazione e manipolazione rimane indefinita. Perché questo è il punto che col tempo è rimasto sostanzialmente irrisolto.
Vedremo come si svilupperà e come andrà a finire anche questa vicenda.
La vicenda del contratto col Pentagono rivela come opera Sam Altman: solidarietà a parole mentre persegue i suoi obiettivi e scuse solo quando il danno d’immagine è fatto. I fatti raccontano un profilo diverso dall’immagine pubblica.
Sam Altman ha un modo particolare di muoversi nelle situazioni di crisi. Dice le cose giuste al momento giusto, si posiziona dalla parte di chi appare più debole, esprime comprensione e solidarietà.
E intanto agisce in direzione opposta. La vicenda del contratto tra OpenAI e il Pentagono, con tutto quello che è successo tra il 26 febbraio e il 3 marzo, offre una dimostrazione plastica di questo schema.
Un meccanismo che si ripete
Chi segue le vicende dell’intelligenza artificiale conosce già questo meccanismo.
Altman lo ha usato più volte nel corso degli anni, con variazioni minime ma sempre con la stessa struttura di fondo: dichiarazioni pubbliche di principio accompagnate da azioni che vanno nella direzione opposta. Seguite poi da correzioni tardive presentate come ripensamenti spontanei.
Questa volta però i fatti si sono susseguiti con una velocità tale da rendere il meccanismo visibile e chiaro a tutti. E vale la pena di ricostruirli non tanto per raccontare cosa è successo, che ormai è noto, ma per mostrare come Altman si è mosso in ogni passaggio.
Sam Altman e il posizionamento preventivo
Giovedì 26 febbraio, quando è già chiaro che Anthropic sta per rompere con il Pentagono, Altman invia un memo interno ai dipendenti di OpenAI. Nel memo scrive che l’azienda condivide le stesse “linee rosse” di Anthropic sulla sorveglianza di massa e sulle armi autonome. Si tratta di una mossa che prepara il terreno: qualunque cosa accada il giorno dopo, Altman potrà dire di essersi posizionato dalla parte giusta della storia.
Come noto, il giorno dopo Dario Amodei rifiuta l’ultimatum del Pentagono e Anthropic viene classificata come rischio per la sicurezza nazionale. Trump definisce l’azienda “radicale di sinistra” e ordina alle agenzie federali di smettere di usare Claude.
Ed è in questo momento che il comportamento di Altman diventa rivelatore.
Sam Altman ha rivelato a tutti la sua doppia faccia
Altman e la finta solidarietà
Poche ore dopo il ban di Anthropic, per non dire quasi in contemporanea, Sam Altman annuncia su X l’accordo tra OpenAI e il Pentagono per i sistemi classificati.
Nel post accompagna l’annuncio con parole di solidarietà verso Amodei. Scrive di fidarsi di lui, di credere che Anthropic si preoccupi davvero della sicurezza, definisce il ban “un precedente estremamente spaventoso“.
Sono dichiarazioni che suonano nobili, quasi coraggiose. Ma arrivano mentre Altman sta firmando il contratto che prende esattamente il posto di quello appena strappato al suo concorrente.
È una modalità che si riconosce facilmente una volta che la si è vista una volta. Altman con i suoi modi non attacca mai direttamente. Si posiziona come alleato di chi sta per colpire, esprime comprensione per la sua posizione, e intanto porta a casa il risultato. La solidarietà diventa copertura per il raggiungimento dei suoi interessi.
Il contesto che aggrava la posizione di Altman
C’è un elemento che rende questa vicenda ancora più significativa.
Nella notte tra il 27 e il 28 febbraio, mentre Altman celebrava il suo accordo e Anthropic veniva messa al bando, gli Stati Uniti lanciavano attacchi aerei sull’Iran. Il Wall Street Journal ha riportato che lo US Central Command ha utilizzato Claude per le operazioni: valutazioni di intelligence, identificazione dei bersagli, simulazioni di combattimento. Lo stesso modello che il governo aveva appena dichiarato un pericolo per la sicurezza nazionale veniva impiegato per una missione di guerra.
Altman sapeva certamente che Claude era integrato nei sistemi militari al punto da non poter essere sostituito in tempi brevi. Sapeva che presentarsi come l’alternativa in quel momento preciso gli avrebbe garantito un vantaggio competitivo enorme. Ha scelto di farlo, accompagnando l’operazione con dichiarazioni di solidarietà.
Sam Altman e il mea culpa calibrato
Ieri, lunedì 3 marzo, dopo un fine settimana in cui Claude è salito al primo posto dell’App Store superando ChatGPT, in cui il movimento “Cancel ChatGPT” ha preso piede sui social e in cui i dati hanno mostrato un’emorragia di utenti verso Anthropic, Altman pubblica una nuova nota.
Anche qui la modalità è riconoscibile. Le scuse arrivano solo quando il danno d’immagine è ormai evidente e quantificabile. Non sono il prodotto di una riflessione, ma la risposta a una crisi di reputazione. Altman non dice “ho sbagliato a firmare mentre Anthropic veniva bandita“. Dice “ho sbagliato a comunicare male“. La sostanza dell’azione non viene mai messa in discussione, solo la forma.
Nella nota aggiunge che sta lavorando per inserire nel contratto un linguaggio esplicito contro la sorveglianza domestica e le informazioni acquisite commercialmente, cioè i dati che il governo può comprare dai data broker senza mandato.
Sono esattamente le garanzie che Amodei chiedeva prima di firmare. Ma Altman le aggiunge dopo, quando ormai servono a recuperare credibilità, non a stabilire un principio.
E gli utenti scoprono Claude
Ma c’è ancora un aspetto di questa vicenda che sfugge al controllo di Altman, ed è la reazione del mercato.
Gli utenti hanno visto la stessa sequenza di eventi e ne hanno tratto le loro conclusioni. Hanno visto un CEO che esprime solidarietà mentre firma il contratto che sostituisce il concorrente; hanno visto le scuse arrivare solo dopo che i numeri mostravano un problema; hanno visto le modifiche al contratto presentate come concessioni spontanee quando erano evidentemente una risposta alla pressione. E hanno scelto di conseguenza.
Sam Altman ha costruito negli anni un’immagine pubblica di leader visionario, attento all’etica, preoccupato per le implicazioni dell’intelligenza artificiale.
È un’immagine che ha coltivato con interviste, post sui social, apparizioni pubbliche calibrate. Ma le azioni raccontano una storia diversa, quella di un CEO che sa sempre dove posizionarsi per apparire dalla parte giusta mentre persegue obiettivi che vanno in un’altra direzione.
Questa vicenda non è un incidente di percorso. È la manifestazione di un modo di operare che si ripete con variazioni minime da anni. La solidarietà usata come copertura, le scuse calibrate sul danno d’immagine, le concessioni presentate come principi quando sono risposte alla pressione del momento.
Sono tutti elementi di uno stesso schema, e questa volta si sono manifestati in una sequenza così rapida e visibile da non poter essere ignorati, da nessuno.
Resta da vedere se questa consapevolezza avrà conseguenze durature o se Altman riuscirà ancora una volta a riposizionarsi. Ma intanto i fatti sono chiari, e il profilo che ne emerge è difficile da essere frainteso.
[L’immagine di copertina è modificata da Franz Russo – Credits: Sam Altman speaking at TED” by TED Conference is licensed under CC BY-NC-SA 4.0.]
Anthropic denuncia DeepSeek, MiniMax e Moonshot per distillazione illecita di Claude. Musk replica accusando proprio Anthropic di furto di dati. Tra copyright, Pentagono e geopolitica, emerge l’ipocrisia dell’intero settore IA.
In questo momento il mondo dell’intelligenza artificiale è attraversato da un grande clima di scontro.
Nelle ultime ore si sta parlando molto della denuncia di Anthropic contro tre laboratori cinesi accusati di aver rubato le capacità del modello Claude attraverso una tecnica chiamata distillazione. I numeri sono impressionanti: oltre 16 milioni di interazioni, 24.000 account fraudolenti, prove che secondo l’azienda di San Francisco portano direttamente ai ricercatori di DeepSeek, MiniMax e Moonshot.
Ma immediatamente dopo, Elon Musk fa partire la sua campagna di attacchi contro Anthropic. Una situazione che svela l’enorme ipocrisia che attraversa l’intero settore dell’IA quando si parla di diritti d’autore e proprietà intellettuale. Perché la verità è che nessuno, in questa grande partita della IA, può davvero tirare la prima pietra.
Si tratta di addestrare un modello più piccolo sugli output di uno più avanzato. Tutti i laboratori di frontiera la usano internamente per creare versioni più economiche dei propri sistemi.
Il problema, secondo Anthropic, è che DeepSeek, MiniMax e Moonshot hanno usato questa tecnica per copiare le capacità di Claude senza autorizzazione, violando i termini di servizio e aggirando le restrizioni geografiche.
Claude non è disponibile commercialmente in Cina per ragioni di sicurezza nazionale. Ma attraverso servizi proxy e reti di account fraudolenti, i tre laboratori sarebbero riusciti ad accedere al modello su larga scala.
I dettagli forniti da Anthropic sono piuttosto precisi. DeepSeek avrebbe generato oltre 150.000 scambi focalizzati sulle capacità di ragionamento e sulla creazione di alternative sicure per la censura a domande politicamente sensibili, quelle sui dissidenti, sui leader di partito, sull’autoritarismo.
MiniMax è accusata di oltre 13 milioni di interazioni concentrate su coding agentico e utilizzo di strumenti.
Moonshot avrebbe prodotto più di 3,4 milioni di scambi mirati al ragionamento agentico e alla computer vision.
Anthropic afferma di aver tracciato queste attività attraverso la correlazione degli indirizzi IP, i metadati delle richieste e gli indicatori dell’infrastruttura. In alcuni casi, dice l’azienda, è stato possibile risalire a specifici ricercatori dei laboratori accusati. Quando Anthropic ha rilasciato un nuovo modello durante la campagna di MiniMax, quest’ultima avrebbe reindirizzato quasi la metà del suo traffico entro 24 ore per catturare le capacità del sistema più recente.
Sono accuse gravi e circostanziate. Ma è importante comunque sottolineare che, al momento, si tratta di accuse.
DeepSeek, MiniMax e Moonshot al momento non hanno rispoto.
Non c’è stata alcuna verifica indipendente e non c’è stato alcun procedimento legale. Il fatto che Anthropic presenti prove dettagliate non significa automaticamente che quelle prove siano incontrovertibili.
Intelligenza artificiale, copyright e potere: quando nessuno è innocente
L’attacco di Musk e la distorsione dei fatti
Ed è qui che entra in scena Elon Musk. Poche ore dopo la pubblicazione del blog post di Anthropic, il proprietario di X e di xAI ha lanciato il suo attacco. Il tweet è diretto e apparentemente definitivo: “Anthropic is guilty of stealing training data at massive scale and has had to pay multi-billion dollar settlements for their theft. This is just a fact.”
Anthropic is guilty of stealing training data at massive scale and has had to pay multi-billion dollar settlements for their theft. This is just a fact. https://t.co/EEtdsJQ1Op
Tradotto: Anthropic è colpevole di aver rubato dati di addestramento su scala massiccia e ha dovuto pagare accordi miliardari per il furto. Questo è semplicemente un fatto. A supporto della sua affermazione, Musk ha condiviso screenshot di Community Notes che menzionano un accordo da 1,5 miliardi di dollari.
Ma le cose non stanno esattamente così. E qui dobbiamo essere precisi, perché la differenza tra i fatti e la narrativa di Musk è sostanziale.
Il riferimento è alla causa Bartz et al v. Anthropic PBC, una class action intentata da un gruppo di autori che accusavano l’azienda di Dario Amodei di aver usato i loro libri per addestrare Claude senza autorizzazione.
La causa si è conclusa con una transazione da 1,5 miliardi di dollari, annunciato a settembre 2025. Ma chiamarla condanna per furto non è corretto. E per come la sta diffondendo Musk si tratta quasi di disinformazione.
Ecco cosa è realmente accaduto. A giugno 2025 il giudice William Alsup aveva già stabilito che l’uso dei libri per addestrare Claude costituiva fair use, un uso legittimo secondo il diritto americano. La decisione è stata descritta come exceedingly transformative, estremamente trasformativa. In altre parole: addestrare un modello di IA su opere protette da copyright può essere legale.
Il problema non era l’addestramento in sé, ma il modo in cui Anthropic aveva ottenuto quei libri. Li aveva scaricati da shadow libraries, ossia biblioteche pirata, come Library Genesis e Pirate Library Mirror.
Questo, secondo il giudice, poteva configurare una violazione separata. Ed è su questo punto che si sarebbe dovuto tenere un processo a dicembre 2025, con danni potenziali che avrebbero potuto raggiungere il trilione di dollari in caso di violazione intenzionale.
Anthropic ha scelto di accordarsi per evitare quel rischio. Ha accettato di pagare circa 3.000 dollari per ciascuno dei 500.000 libri coinvolti e di distruggere i dataset contenenti le opere scaricate illegalmente.
Da precisare, non è stata emessa alcuna sentenza di condanna e, quindi, non vi è stato alcun verdetto di colpevolezza. Si è trattato di un accordo volontario per chiudere una controversia. Questo ad onor del vero e senza prendere parti per l’uno o per l’altro.
Inoltre, non c’è alcun riferimento al tracciamento delle persone che alcuni utenti su X hanno iniziato a citare. Questa accusa sembra derivare da una confusione: Anthropic ha tracciato gli IP e i metadati degli account fraudolenti usati dai laboratori cinesi per accedere a Claude, cosa del tutto legale e necessaria per identificare gli abusi. Non ha quindi tracciato utenti comuni.
Il peccato originale dell’IA: tutti hanno lo stesso problema
Ma ecco il punto che nessuno vuole affrontare davvero. Se Anthropic ha problemi con il copyright, li hanno tutti. Nessuno escluso, e questo include xAI di Musk.
OpenAI, l’azienda che ha dato il via alla corsa alla IA generativa con ChatGPT, affronta attualmente oltre 70 cause legali per violazione del copyright. La più nota è quella intentata dal New York Times, che accusa OpenAI e Microsoft di aver usato milioni di articoli per addestrare i loro modelli. A gennaio 2026 un tribunale ha ordinato a OpenAI di produrre 20 milioni di log di ChatGPT come prove. L’azienda ha cercato di resistere invocando la privacy degli utenti, ma il giudice ha respinto le obiezioni.
Meta è stata citata per aver usato LibGen, la stessa biblioteca pirata al centro della causa Anthropic. Email interne emerse durante il procedimento suggeriscono che l’azienda sapeva di star usando materiale piratato. Google è sotto accusa per pratiche simili. Disney e Universal hanno fatto causa a Midjourney per violazione del copyright sulle immagini.
E poi c’è xAI, l’azienda di Musk. A dicembre 2025 il giornalista John Carreyrou, oggi del NYT, quello che ha smascherato lo scandalo Theranos, ha intentato una causa contro sei aziende di IA per l’uso non autorizzato dei suoi libri. Tra i convenuti c’è xAI: è la prima causa per copyright contro Grok. La risposta dell’azienda? Due parole: “Legacy Media Lies”. Le bugie dei media tradizionali.
Ma i problemi di xAI non si fermano qui. Grok è addestrato sui contenuti degli utenti di X, e questa pratica ha già attirato l’attenzione dei regolatori di diversi paesi.
Nel 2024 X ha attivato di default l’opzione che consente di usare i post degli utenti per addestrare Grok. Non opt-in, ma opt-out. Chi non voleva partecipare doveva andare nelle impostazioni e disattivare manualmente la funzione. Questo ha scatenato l’intervento del Garante irlandese per la protezione dei dati, che a settembre 2024 ha ottenuto la sospensione permanente dell’uso dei dati degli utenti UE per l’addestramento di Grok, oltre all’ordine di cancellare i dati già acquisiti.
Ad aprile 2025 è stata aperta un’indagine formale sulla legalità del trattamento storico dei dati. E i nuovi termini di servizio di X, entrati in vigore a gennaio 2026, hanno ampliato ulteriormente la definizione di contenuti che l’azienda può usare: ora include esplicitamente input, prompt e output delle conversazioni con Grok. Il tutto senza possibilità di opt-out.
Cosa significa questo in parole povere. Significa che tutto quello che gli utenti scrivono a Grok e tutto quello che Grok risponde diventa materiale che xAI può usare liberamente per addestrare i suoi modelli futuri. E l’utente non non ha modo di opporsi.
C’è poi la questione delle immagini. Grok ha generato contenuti sessualmente espliciti non consensuali, i cosiddetti deepfake, che hanno portato a denunce penali in Francia e al blocco del servizio in Malesia e Indonesia. La Federal Trade Commission americana ha aperto un’indagine sulle pratiche di xAI relative ai minori.
Quindi quando Musk accusa Anthropic di aver rubato dati, sta parlando di un’azienda che ha raggiunto un accordo transattivo su una questione che riguarda l’intero settore, mentre la sua stessa azienda è sotto causa per le stesse ragioni e usa i dati degli utenti della sua piattaforma social senza un consenso realmente informato.
Lo scontro per i contratti con il Pentagono
Ma perché Musk sta attaccando Anthropic proprio adesso? La risposta sta in quello che è successo nelle ultime settimane al Pentagono.
Anthropic è attualmente l’unica azienda di IA approvata per operare sulle reti militari classificate americane. Claude sarebbe stato usato durante l’operazione che ha portato alla cattura del presidente venezuelano Nicolás Maduro a gennaio 2026, il primo caso documentato di IA impiegata in un raid militare attivo. Ma il rapporto tra Anthropic e il Pentagono si è deteriorato rapidamente.
Il Segretario della Difesa Pete Hegseth ha emesso una direttiva a gennaio che richiede a tutte le aziende di IA di rimuovere qualsiasi restrizione sull’uso militare dei loro modelli, consentendo qualsiasi uso legale. Anthropic ha rifiutato.
L’azienda insiste sulle sue posizioni fondanti: niente sorveglianza di massa degli americani, niente armi autonome che possano sparare senza supervisione umana.
Dario Amodei, il CEO di Anthropic, ha scritto in un saggio a gennaio: “Un’IA potente che analizza miliardi di conversazioni di milioni di persone potrebbe misurare il sentimento pubblico, individuare sacche di slealtà in formazione e schiacciarle prima che crescano.” Questa frase, che descrive un rischio, è stata usata contro di lui come prova di una presunta ostilità verso gli interessi americani.
Per oggi, 24 febbraio, Hegseth ha convocato Amodei al Pentagono per quello che fonti interne descrivono come un incontro non amichevole. Uan sorte di resa dei conti.
Un funzionario della Difesa ha detto ad Axios: “Questo non è un incontro per conoscersi. Questo è un incontro del tipo: o ti decidi o te ne vai.”
Il Pentagono sta minacciando di designare Anthropic come rischio per la catena di approvvigionamento, una classificazione normalmente riservata ad avversari stranieri. Questo annullerebbe i contratti e costringerebbe altri partner del Pentagono a smettere di usare Claude.
Nel frattempo, xAI ha accettato tutte le condizioni. Grok entrerà nelle reti militari classificate senza restrizioni. L’accordo è stato firmato ed è in questo contesto che Musk sta attaccando Anthropic su X. Tutto questo, mentre la sua azienda si posiziona per sostituire il concorrente nei contratti più sensibili del governo americano.
Cosa ci racconta davvero questa storia
La denuncia di Anthropic contro i laboratori cinesi è seria e merita attenzione. Se le prove presentate sono accurate, siamo di fronte a un caso significativo di appropriazione illecita di proprietà intellettuale che solleva questioni importanti sulla sicurezza nazionale e sulla competizione tecnologica tra Stati Uniti e Cina.
Ma questa storia ci dice anche qualcos’altro.
Ci dice che l’intero settore dell’intelligenza artificiale è nato e cresciuto su fondamenta traballanti quando si parla di diritti d’autore. Tutti i grandi modelli sono stati addestrati su contenuti protetti, spesso senza autorizzazione, talvolta scaricati da fonti pirata. Le cause legali si moltiplicano. Gli accordi transattivi cominciano ad arrivare. E la questione di cosa sia lecito e cosa no nell’addestramento di un’IA è ancora largamente irrisolta.
Musk accusa gli altri delle stesse cose che lui ha già commesso. Solo che non lo ammetterà mai ed è per questo che sta scatenando la sua campagna contro Anthropi, usando X come megafono di disinformazione e distrazione.
Questa storia dice, infine, che il controllo delle piattaforme di informazione da parte di soggetti con interessi commerciali diretti nel settore che dovrebbero coprire crea distorsioni evidenti.
Quando il proprietario di X è anche il proprietario di un’azienda di IA che compete per contratti governativi, ogni suo post su quel tema va letto con questo tenendo bene in mente tutto questo.
La verità è che in questo grande clima di scontro all’interno della IA nessuno è innocente. Ma alcuni stanno facendo molto più rumore degli altri per coprire i propri problemi mentre amplificano quelli altrui.
Un momento di forte imbarazzo all’India AI Impact Summit tra Sam Altman e Dario Amodei ha catturato l’attenzione di tutti. In realtà, alla base di quell’imbarazzo c’è uno scontro tra due modi diversi di intendere il futuro della IA.
Al Bharat Mandapam si sono dati appuntamento i CEO delle principali aziende tecnologiche del pianeta, con oltre 200 miliardi di dollari in promesse di investimento e l’attenzione dei media di tutto il mondo.
Sul palco, dopo i keynote, il premier indiano, e padrone di casa, Narendra Modi invita i tredici leader presenti a unire le mani in segno di coesione e collaborazione.
Un gesto per lo più pensato a favore delle telecamere, per celebrare l’unità di un settore che promette di cambiare il mondo. La folla applaude e tutti, o quasi, seguono l’indicazione di Modi.
Ma succede qualcosa su quel palco che finisce per rubare la scena.
Altman, Amodei e la grande frattura dell’intelligenza artificiale
L’imbarazzo tra Sam Altman e Dario Amodei
Sam Altman, CEO di OpenAI, e Dario Amodei, CEO di Anthropic, sono uno accanto all’altro.
Altman, che ha alla sua destra proprio il premier indiano Modi, abbassa lo sguardo, visibilmente imbarazzato, verso la mano di Amodei. C’è un breve momento di contatto visivo imbarazzato, poi entrambi evitano di guardarsi.
Amodei, anche lui indeciso su cosa fare, si guarda intorno con un gesto che sembra dire “chi, io?”. Per diversi secondi, che sembrano interminabili, i due evitano goffamente il contatto.
Alla fine, entrambi alzano un pugno chiuso invece di unire le mani.
Il video, ovviamente, fa il giro delle piattaforme nel giro di pochissimi minuti. In molti lo descrivono come l’emblema della “AI cold war”, la guerra fredda dell’intelligenza artificiale.
“Non sapevo cosa stesse succedendo”, dirà poi Altman ai media indiani. “Ero confuso. Modi mi ha preso la mano e l’ha alzata, e non ero sicuro di cosa dovessimo fare.
Ma la confusione di Altman è difficile da credere. Quei due pugni alzati separatamente raccontano invece una storia che inizia cinque anni prima, in una sala riunioni di San Francisco. E che nelle ultime settimane è esplosa in uno scontro pubblico senza precedenti.
An awkward moment between OpenAI CEO Sam Altman and Anthropic CEO Dario Amodei at an AI Summit Thursday captured the increasingly icy relations between two rival tech leaders who started off as colleagues. https://t.co/HR4E8B4e3Cpic.twitter.com/jjpbmkBh34
Amodei, come molti già sapranno, ha lavorato sotto Altman a OpenAI dal 2016 al 2020, come vicepresidente della ricerca. Si è concentrato sulla sicurezza, ha avuto un ruolo chiave nel lancio di GPT-2 e GPT-3, ha co-inventato il “reinforcement learning from human feedback”, la tecnica che usa l’input umano per addestrare i modelli linguistici a produrre risultati migliori.
Ma poi qualcosa si rompe, cosa che succede in tutte le storie aziendali.
Amodei, insieme a un piccolo gruppo di colleghi, inizia a preoccuparsi per la direzione che sta prendendo OpenAI. La tensione riguarda un aspetto fondamentale. Lo sviluppo dell’intelligenza artificiale deve dare priorità alla velocità per conquistare il mercato, oppure procedere con cautela, investendo nella ricerca sulla sicurezza prima di rilasciare nuovi modelli?
Per Amodei la risposta è chiara. In un’intervista ha spiegato che semplicemente scalare i modelli con più potenza di calcolo non basta: “Serviva qualcosa in aggiunta allo scaling, ovvero l’allineamento o la sicurezza.”
“Prendi alcune persone di cui ti fidi e vai a realizzare la tua visione“, si disse Amodei, piuttosto che continuare a discutere all’interno di un’organizzazione dove altri avevano il potere decisionale.
E così, nel 2021, lascia OpenAI insieme alla sorella Daniela e una dozzina di ex colleghi. Fondano Anthropic con una missione precisa: mettere la sicurezza al primo posto.
Da allora la frattura tra i due si è trasformata in una guerra commerciale che riflette due visioni opposte del futuro.
OpenAI CEO Sam Altman and Anthropic CEO Dario Amodei visibly declined to hold hands during a group photo at the India AI Impact Summit, even as other leaders on stage linked arms for the ceremonial shot pic.twitter.com/J1eGShSkiK
Da una parte c’è chi guarda già oltre l’AGI, l’intelligenza artificiale generale, verso la superintelligenza.
Altman ha scritto che “strumenti superintelligenti potrebbero accelerare massicciamente la scoperta scientifica e l’innovazione ben oltre ciò che siamo capaci di fare da soli.” Sa che suona come fantascienza, ammette che sembra quasi folle parlarne. Ma non gli importa: “Ci siamo già passati e siamo a nostro agio nel tornarci.”
Dall’altra c’è chi dedica il suo tempo a parlare dei pericoli. Amodei ha detto in un’intervista televisiva: “Mi preoccupo molto delle incognite. Non credo che possiamo prevedere tutto con certezza. Ma proprio per questo stiamo cercando di prevedere tutto ciò che possiamo. Pensiamo agli impatti economici dell’IA. Pensiamo all’uso improprio. Pensiamo alla perdita di controllo del modello.”
E ha scritto qualcosa di insolito per il CEO di un’azienda del settore: “È un po’ imbarazzante dirlo come CEO di un’azienda IA, ma penso che il prossimo livello di rischio siano proprio le stesse aziende IA. Controllano grandi data center, addestrano modelli di frontiera, e in alcuni casi hanno contatto quotidiano con decine o centinaia di milioni di utenti. Potrebbero usare i loro prodotti per fare il lavaggio del cervello alla loro enorme base di utenti.“
La domanda che sta dietro a tutto questo l’ha posta un giornalista in un’intervista: “Nessuno ha scelto questo. Chi ha eletto te e Sam Altman?” La risposta di Amodei è stata disarmante: “Nessuno, onestamente nessuno. E questa è una ragione per cui ho sempre sostenuto una regolamentazione responsabile della tecnologia.”
Lo scontro tra OpenAI e Anthropic al Super Bowl
La rivalità filosofica è diventata guerra aperta poche settimane fa. OpenAI ha annunciato che inizierà a testare la pubblicità all’interno di ChatGPT per gli utenti gratuiti.
Anthropic, dal canto suo, ha risposto durante il Super Bowl con una serie di spot satirici che prendevano di mira questa decisione.
Ogni spot si apriva con una singola parola a tutto schermo: “tradimento”, “inganno”, “slealtà”, “violazione”. In ciascuno di essi, persone comuni che cercavano consigli da un assistente IA venivano interrotte da pubblicità indesiderate. Il messaggio di fondo era: noi non lo faremo mai.
Altman ha risposto con un lungo post su X, accusando gli spot di essere “ingannevoli” e definendo Anthropic un’azienda “autoritaria”. Ha ammesso di aver trovato gli spot “divertenti”, come a voler convincere che sapeva stare allo scherzo.
Ma poi ha rincarato la dose: “Anthropic serve un prodotto costoso a persone ricche. Più texani usano ChatGPT gratis di quante persone in totale usino Claude negli USA.”
Lo scontro va oltre il marketing. Anthropic ha annunciato un investimento di 20 milioni di dollari in un super PAC che si oppone a un altro super PAC vicino a OpenAI. Da una parte si combatte per una regolamentazione più forte dell’intelligenza artificiale, dall’altra si preferisce un approccio laissez-faire.
Ed è in questo clima che i due si sono ritrovati uno accanto all’altro sul palco di New Delhi, per tornare al tema di questo articolo.
Un’immagine imbarazzante che in realtà dice tutto
Durante i loro interventi al Summit, i messaggi hanno preso strade divergenti. Amodei ha parlato dei “rischi seri” legati ai sistemi IA avanzati: comportamento autonomo, uso improprio da parte di governi e malintenzionati, spostamento economico.
Altman ha sostenuto che la sicurezza dell’IA deve includere la “resilienza sociale” e che “nessun laboratorio IA può garantire un buon futuro da solo.”
Poi è arrivato il momento della foto di gruppo. E quei pugni alzati, invece delle mani unite, hanno detto più di qualsiasi altro discorso.
La frattura non riguarda solo due CEO o due aziende. Attraversa l’intero settore dell’intelligenza artificiale e mette al centro due modi di intendere la IA molto diversi.
Da una parte chi corre verso l’AGI puntando sulla velocità e sulla democratizzazione dell’accesso. Dall’altra chi frena e chiede tempo per capire che cosa stiamo costruendo.
Due visioni che necessitano comunque di regole
Due visioni che dovrebbero essere al centro, a questo punto, di qualsiasi dibattito nella società.
Se è vero, come è vero, che la IA sta correndo a velocità molto sostenuta; se è vero che le aziende stanno investendo moltissimo sulla IA, e già si parla di bolla per via di investimenti esagerati, è anche vero che questo fenomeno ancora non è molto regolamentato.
L’UE, dal canto suo, e nonostante le tante debolezze di tipo tecnologico e infrastrutturale, ha sicuramente indicato una strada con l’AI Act. Ma serve fare di più, e meglio.
Il problema è che provare a regolamentare meglio e a cercare di tenere il passo della IA in questa fase storica è molto complicato, per via delle grandi tensioni geopolitiche in atto.
Inevitabilmente, la IA diventa un terreno da coltivare ma anche un terreno di scontro per il fatto che in gioco ci sono interessi altissimi.
In mezzo a tutto questo, resta la domanda che nessuno ha ancora il coraggio di affrontare: ma chi è che ha dato a un pugno di ingegneri della Silicon Valley il diritto di decidere il futuro dell’IA e, quindi, dell’umanità?
Mark Zuckerberg ha testimoniato davanti alla giuria del caso KGM. Una testimonianza a tratti molto tesa dove, in sostanza, Zuckerberg in modo netto ha anche sottolineato il suo potere all’interno di Meta. Un caso che tocca anche l’UE.
Non era la prima volta che il fondatore di Meta rispondeva di fronte a un’istituzione: nel 2018 aveva già affrontato il Congresso americano, e in quell’occasione aveva persino chiesto scusa alle famiglie colpite dai danni dei social.
Ma era la prima volta che Mark Zuckerberg lo faceva sotto giuramento, davanti a dodici giurati chiamati a decidere se Instagram sia una piattaforma dannosa.
Il caso, come già ricordato, vede coinvolta KGM contro le piattaforme digitali, nello specifico Meta e YouTube.
La protagonista di questa vicenda è Kaley, una ventenne californiana identificata negli atti giudiziari con le sole iniziali per tutelarla. Kaley ha iniziato a usare YouTube a sei anni; a nove era già su Instagram; a undici, secondo i documenti del processo, il suo profilo era attivo quotidianamente. La sua storia fatta di dipendenza digitale, depressione, pensieri suicidari è diventata il cuore di una battaglia legale che va ben oltre la sua vicenda personale.
Un processo che vale 1.600 cause
Il caso KGM è quello che negli Stati Uniti si chiama un “bellwether trial”, un processo-campione. Il suo esito potrebbe influenzare l’andamento di oltre 1.600 cause simili, già consolidate e in attesa di sentenza, oltre a più di 2.300 procedimenti paralleli depositati da genitori, distretti scolastici e procuratori generali statali.
TikTok e Snap hanno già patteggiato prima dell’inizio del dibattimento e, quindi, restano in piedi Meta e Google, che risponde per YouTube.
La tesi dell’accusa è semplice nelle parole, quanto complessa nelle prove: le piattaforme non sono strumenti neutrali ma prodotti progettati intenzionalmente per agganciare gli utenti più giovani, sfruttando le loro vulnerabilità neurologiche.
Un “casinò digitale”, secondo la definizione usata dall’avvocato dell’accusa Mark Lanier. La difesa risponde che la complessità della salute mentale adolescenziale non può essere ridotta all’uso di un’app.
Per decenni Big Tech ha goduto della protezione offerta dalla Section 230 del Communications Decency Act del 1996, una norma che esclude le piattaforme dalla responsabilità per i contenuti pubblicati dagli utenti.
Ma in questa occasione l’accusa ha adottato un’altra strada: aggirare il 230 applicando le leggi sulla responsabilità del produttore. Non si contesta quello che gli utenti pubblicano, ma come la piattaforma è stata progettata. È la stessa logica che negli anni Novanta ha trascinato in tribunale le grandi case del tabacco, se possiamo avanzare questo esempio.
Ecco cosa ha davvero detto Mark Zuckerberg nel caso KGM
Zuckerberg in aula: i documenti interni che scottano
La testimonianza di Mark Zuckerberg è durata ore e ha riservato momenti di tensione evidente. L’avvocato Lanier ha costruito la sua strategia attorno ai documenti interni di Meta, portando in aula email e report che la società non avrebbe mai voluto vedere proiettati su uno schermo davanti a una giuria.
Il primo elemento riguardava gli obiettivi di crescita.
Lanier ha mostrato un’email del 2015 in cui Zuckerberg scriveva di voler aumentare del 12% in tre anni il tempo che gli utenti trascorrevano su Instagram. Il fondatore ha risposto di non ricordare se fosse un obiettivo ufficiale, aggiungendo che Meta cerca di creare servizi utili e che le persone continuano a usarli perché li trovano validi. Un’affermazione che, nel contesto del processo, è sembrata una risposta preparata per l’occasione.
Più pesante il documento del 2020, che mostrava come gli undicenni avessero quattro volte più probabilità di tornare su Facebook rispetto agli utenti adulti. “Persone che si iscrivono a Facebook a undici anni?“, ha chiesto Lanier sarcasticamente. “Pensavo che non ne aveste.”
Zuckerberg ha confermato che molti utenti mentono sull’età per accedere alla piattaforma, definendo la verifica “molto difficile”.
Ma è il documento datato 2017 quello che ha lasciato meno margine di manovra al fondatore di Facebook poi diventata Meta.
Un’email interna recitava testualmente: “Mark ha deciso che la priorità principale dell’azienda nel 2017 sono gli adolescenti“.
Zuckerberg, incalzato, ha risposto che “il contesto suggerisce che sia corretto“, di fatto confermando il contenuto senza smentirlo. E un documento del 2018 riportava la frase: “Se vogliamo vincere in grande con i teenager, dobbiamo portarli dentro da tweens“, cioè prima dei tredici anni, che è l’età minima prevista dalla stessa policy di Instagram.
La strategia dei “tweens” e i filtri estetici
Un altro capitolo della testimonianza nel caso KGM ha riguardato i filtri estetici di Instagram.
Quando i propri esperti interni avevano segnalato che quei filtri, che modificano l’aspetto del viso, levigano la pelle, alterano i lineamenti, contribuivano a problemi di immagine corporea nelle ragazze giovani, Zuckerberg aveva deciso di non eliminarli.
La sua spiegazione in aula, in sostanza, è stata: rimuoverli avrebbe significato fare una scelta paternalistica. “Abbiamo permesso alle persone di usarli se lo desideravano“, ha detto, “ma abbiamo smesso di raccomandarli attivamente“.
Il momento più teatrale è arrivato quando Lanier ha fatto srotolare in aula, con l’aiuto di sei avvocati, un collage largo dieci metri con centinaia di selfie che Kaley aveva pubblicato su Instagram negli anni della sua dipendenza.
L’avvocato ha chiesto a Zuckerberg di osservarli. Il suo account era mai stato monitorato per un uso così massiccio da parte di una bambina? Il CEO non ha risposto. Kaley ha assistito alla testimonianza dalla galleria del tribunale riservata al pubblico.
Nel corso della deposizione, Zuckerberg è apparso visibilmente irritato. “Non è quello che sto dicendo“, “Stai fraintendendo le mie parole“, “Stai travisando quello che ho detto“, le sue risposte sono diventate più taglienti man mano che le ore passavano.
Quando invece è toccato all’avvocato della difesa fare le domande, il tono si è fatto più disteso. Zuckerberg ha sostenuto che esiste un malinteso di fondo: più tempo trascorso sulla piattaforma non significa automaticamente più profitti, perché “se le persone non hanno una buona esperienza, perché continuerebbero a usarla?”.
Zuckerberg e la conferma del suo potere su Meta
Non sono mancati i momenti di tensione per Zuckerberg.
Specie nel momento in cui gli avvocati hanno avanzato il dubbio che avesse mentito in una intervista al podcast di Joe Rogan, lo scorso anno, riguardo all’impossibilità che il CdA di Meta potesse mai licenziarlo.
In quella occasione disse di non essere particolarmente preoccupato, ma di fronte agli avvocati ha risposto: “Se il consiglio volesse licenziarmi, potrei eleggere un nuovo consiglio e reintegrarmi”.
Un messaggio chiaro e limpido. In sostanza Zuckerberg in aula ha voluto sottolineare il suo totale controllo di Meta. La sua non è una figura paragonabile a qualsiasi altro CEO, quindi sostituibile. Con quella frase Zuckerberg ha voluto marcare il concetto che la sua leadership all’interno di Meta è blindata e che il board non è un potere avverso all’interno dell’azienda. Tutt’altro.
Meta è strettamente legata alle sorti di Mark Zuckerberg ed è un tema che assume una certa rilevanza in questo periodo in cui si parla sempre più della diretta responsabilità dei proprietari delle piattaforme, specie in UE.
Ecco perché questo processo interessa anche l’UE
Il caso KGM non è solo una storia americana. In Italia, in Germania, in Francia, in Spagna e nel resto dell’UE, il dibattito sulla responsabilità delle piattaforme nei confronti dei minori si è acceso in particolar modo nelle ultime settimane.
Come abbiamo visto nei giorni scorsi, avanzano proposte di legge a difesa dei minori sulle piattaforme nei paesi UE e, in particolar modo, si fa strada il metodo Spagna che punta a mettere nel mirino proprio la responsabilità diretta dei proprietari delle piattaforme e dei senior manager.
Una sentenza favorevole a Kaley potrebbe avere conseguenze anche oltre l’Atlantico, non tanto per effetto giuridico diretto ma per pressione politica e reputazionale.
Sarebbe la conferma, dopo anni di dibattiti, che le piattaforme, e forse anche i proprietari, possono essere ritenute responsabili non solo per ciò che i loro utenti pubblicano, ma per il modo in cui sono state costruite per trattenerli.
La giuria del Los Angeles Superior Court dovrà raggiungere un accordo con nove voti su dodici per emettere un verdetto. La sentenza è attesa entro fine marzo 2026.
Nel frattempo, fuori dal palazzo di giustizia, genitori che hanno perso i loro figli a causa di dinamiche legate all’uso dei social media continuano ad attendere. Molti di loro tenevano in mano una foto dei propri figli che non ci sono più.
Il DPC irlandese avvia un’indagine su Grok per immagini sessualizzate non consensuali, ai sensi del GDPR. È il terzo fronte regolatorio UE contro X, che rischia sanzioni fino al 4% del fatturato globale.
Il Data Protection Commission (DPC) irlandese ha notificato a X l’avvio di un’indagine formale su Grok, la IA integrata sulla piattaforma. L’oggetto dell’inchiesta è verificare se il trattamento dei dati personali da parte del chatbot di xAI viola il GDPR, il regolamento europeo sulla protezione dei dati.
Graham Doyle, vice commissario del DPC, ha spiegato che l’autorità sta interagendo con X Internet Unlimited Company (XIUC), la società irlandese che gestisce le operazioni europee della piattaforma di Elon Musk, da quando sono emersi i primi report sulla possibilità di usare l’account @Grok su X per generare questo tipo di contenuti. E ora si passa dalle interlocuzioni informali a un’indagine strutturata.
Perché l’Irlanda è al centro di tutto
Il DPC irlandese è il regolatore principale per X in tutta l’Unione Europea, perché le operazioni europee dell’azienda hanno sede a Dublino. Questo significa che l’indagine irlandese ha valore per tutti i 27 stati membri dell’UE e per lo Spazio Economico Europeo.
Le sanzioni potenziali posso arrivare fino al 4% del fatturato globale dell’azienda. Per un’azienda delle dimensioni di X, parliamo di cifre nell’ordine di centinaia di milioni di euro.
Ma c’è un aspetto che rende questa indagine particolarmente rilevante. Il DPC ha avviato quella che definisce una “large-scale inquiry”, un’indagine su larga scala che esaminerà la conformità di X agli obblighi fondamentali del GDPR: i principi del trattamento dati; la liceità del trattamento; la protezione dei dati fin dalla progettazione e per impostazione predefinita; e l’obbligo di condurre una valutazione d’impatto sulla protezione dei dati.
Il DPC irlandese indaga sulle immagini di nudo pubblicate su X
Grok e il terzo fronte europeo
L’indagine del DPC si aggiunge a due procedimenti già aperti. Il 26 gennaio la Commissione Europea ha avviato un’indagine per verificare se Grok diffonde contenuti illegali ai sensi del Digital Services Act.
E il 3 febbraio l’autorità britannica per la privacy, l’ICO, ha aperto un’indagine analoga a quella irlandese, sempre focalizzata sul GDPR e sulla generazione di immagini sessualizzate.
Tre indagini diverse, tre autorità diverse, ma tutte puntate sullo stesso problema: un chatbot che genera immagini di nudo non consensuali senza filtri efficaci.
Grok e cosa è successo a gennaio
Per capire il contesto di questa indagine bisogna tornare a quanto accaduto nelle prime settimane del 2026.
Come già ricordato, a fine 2025 X ha rilasciato la possibilità delle modifiche delle immagini direttamente nei post pubblici, quindi visibili a tutti.
A distanza di pochi giorni, a gennaio, Grok ha iniziato a generare immagini sessualizzate su richiesta degli utenti in modo massiccio. Un’inchiesta riportata anche da Bloomberg ha quantificato il fenomeno: circa 6.700 immagini sessualizzate all’ora, 84 volte più dei principali siti dedicati ai deepfake. L’85% delle immagini prodotte da Grok era classificabile come contenuto sessualizzato.
Le storie delle vittime hanno fatto il giro dei media internazionali.
Donne che si ritrovavano versioni nude delle proprie foto pubblicate su X, senza aver dato alcun consenso e senza strumenti efficaci per rimuoverle. Una di loro aveva pubblicato una foto con il fidanzato in un bar: due sconosciuti l’hanno modificata usando Grok, prima mettendola in bikini, poi sostituendo il bikini con un filo interdentale. Ha segnalato le immagini a X. Non ha mai ricevuto risposta.
X, in risposta al fenomeno dilagante, ha poi annunciato alcune restrizioni, limitando la generazione di immagini agli abbonati paganti. Ma le verifiche condotte da Reuters all’inizio di questo mese hanno dimostrato che Grok continuava a produrre immagini sessualizzate quando sollecitato.
La differenza tra DSA e GDPR
L’indagine della Commissione Europea si muove sul binario del Digital Services Act, il regolamento che disciplina i contenuti online e la moderazione delle piattaforme. È lo stesso regolamento che a dicembre 2025 ha portato a una multa di 120 milioni di euro contro X per la questione delle spunte blu ingannevoli.
L’indagine del DPC irlandese si muove invece sul binario del GDPR, che riguarda specificamente la protezione dei dati personali. Sono due strumenti diversi, con logiche diverse e sanzioni diverse. E X rischia, appunto, su entrambi i fronti.
Il GDPR richiede che il trattamento dei dati personali sia lecito, corretto e trasparente. Richiede che i dati siano raccolti per finalità determinate e trattati in modo compatibile con quelle finalità.
Richiede una valutazione d’impatto quando il trattamento può comportare rischi elevati per i diritti delle persone. Generare immagini sessualizzate di persone reali senza il loro consenso, infatti, solleva questioni su tutti questi punti.
La risposta di Musk e le tensioni con l’UE
La posizione di Elon Musk e della sua amministrazione sulle regolamentazioni UE è nota. Musk ha espresso più volte le sue obiezioni alle norme UE sui contenuti online. L’amministrazione Trump ha descritto le multe imposte alle aziende tecnologiche americane come una forma di tassazione.
Ma le autorità UE non sembrano intenzionate a fare passi indietro. La Commissione ha già ordinato a X di conservare tutti i documenti relativi a Grok fino alla fine del 2026. È un segnale, come ricordato, che indica la costruzione di un dossier per eventuali azioni future.
Cosa c’è da aspettarsi
L’indagine del DPC richiederà tempo, settimane o mesi. Ma il fatto che si sia passati da interlocuzioni informali a un procedimento formale indica che il DPC ha ritenuto insufficienti le risposte di X alle prime sollecitazioni.
Nel frattempo, negli Stati Uniti il Take It Down Act prevede che le piattaforme si adeguino entro maggio 2026. È una legge che riguarda specificamente la rimozione di immagini intime non consensuali, incluse quelle generate dall’intelligenza artificiale.
Il Take It Down Act (approvato negli USA a maggio 2025) è una legge federale statunitense che obbliga le piattaforme online a rimuovere immagini e video intimi non consensuali (inclusi deepfake e revenge porn) entro 48 ore dalla segnalazione, garantendo una maggiore protezione delle vittime di abusi digitali e pornografia generata da IA.
X si trova quindi sotto pressione su più fronti: UE, Regno Unito, Stati Uniti.
E al centro di tutto c’è Grok, il chatbot che Musk ha promosso come più divertente e irriverente degli altri. Quella irriverenza, però, rischia di costare molto cara.
X dichiara 1 miliardo di dollari in ricavi annuali dagli abbonamenti Premium. Ma i numeri raccontano una storia più complessa, tra promesse non mantenute e contraddizioni sui dati degli utenti.
X, per voce di Nikita Bier, responsabile di prodotto, sostiene di aver realizzato 1 miliardo di dollari in ricavi ricorrenti annualizzati dagli abbonamenti. La notizia è stata data durante una riunione plenaria di xAI tenutosi martedì scorso.
La notizia, riportata da The Information, è stata immediatamente rilanciata come un successo. Ma come spesso accade con i numeri che escono dall’orbita di Musk, vale la pena guardarci dentro con attenzione.
Un dato da contestualizzare
Il primo elemento da chiarire riguarda la natura del dato. Si tratta infatti di annualized recurring revenue, ossia una proiezione basata sul ritmo attuale dei ricavi, non di un consuntivo certificato.
È una metrica usata dalle aziende in crescita per mostrare il potenziale, ma che può sovrastimare la realtà se il trend non si mantiene costante.
Il secondo elemento è il contesto. A inizio 2025, gli utenti abbonati ai servizi Premium erano circa 650.000, vale a dire meno dello 0,2% dei 580 milioni di utenti attivi mensili dichiarati all’epoca.
Stime indipendenti indicavano ricavi da abbonamenti intorno ai 200 milioni di dollari all’anno. Un miliardo rappresenterebbe quindi una crescita di cinque volte in meno di dodici mesi. Possibile, ma il dato non è verificabile dall’esterno, visto che X è una società privata e non pubblica bilanci.
Come nota Social Media Today, il miliardo resta comunque lontano dai ricavi pubblicitari, che nel 2024 rappresentavano ancora circa il 68% del fatturato totale di X, stimato intorno ai 2,5 miliardi di dollari.
Per un confronto: Snapchat ha dichiarato 750 milioni di dollari da Snapchat+ (la versione a pagamento dell’app di Evan Spiegel che offre l’accesso a funzionalità esclusive, sperimentali e in anteprima) nel 2025. Il traguardo di X è quindi plausibile, ma non rappresenta la svolta che la narrazione interna vorrebbe suggerire.
X e 1 miliardo di dollari di abbonamenti, cosa dicono davvero i numeri
Il dubbio sul numero degli utenti di X
Nello stesso meeting, Musk ha fornito dati sugli utenti che meritano un’analisi attenta. Ha parlato di “1 miliardo di utenti”, ma la cifra si riferisce alle app installate, non agli utenti attivi.
Gli utenti attivi mensili, ha ammesso lo stesso Musk, sono “in media circa 600 milioni”. Ma c’è di più: pochi giorni prima, lo stesso Bier aveva scritto su X di occuparsi del supporto clienti per “500 milioni di persone”.
Quindi X ha 500 milioni, 600 milioni o un miliardo di utenti? Dipende da come si vogliono presentare i numeri.
È un esempio di quella che potremmo chiamare la contabilità creativa della comunicazione di Musk: i dati vengono selezionati e presentati per costruire la narrazione più favorevole, lasciando agli osservatori esterni il compito di ricostruire il quadro reale.
Come avevo già analizzato in un precedente approfondimento sulla situazione di X, la piattaforma ha vissuto un’emorragia di utenti e inserzionisti dopo l’acquisizione del 2022. I segnali di ripresa ci sono, ma vanno letti con cautela.
Grok e la monetizzazione di uno scandalo
Va detto che sull’aumento dei ricavi da abbonamenti gioca un peso anche Grok, l’intelligenza artificiale sviluppata da xAI e integrata in X. L’IA generativa può essere usata anche senza abbonamento ma con forti limitazioni d’uso, ma evidentemente con abbonamento come Premium e Premium + (38 euro al mese effettuando il pagamento da web) le possibilità aumentano.
Ricorderete anche che per limitarlo da un utilizzo esteso a tutti con tutto quello a cui abbiamo assistito, la possibilità di generare immagini con richieste testuali pubbliche sia adesso limitata a chi ha almeno un abbonamento Premium.
Un modo per monetizzare anche su uno scandalo che ancora non si è esaurito del tutto.
X Money è quasi realtà
Nello stesso meeting, Musk ha annunciato che X Money, il sistema di pagamenti integrato, entrerà in beta esterna “entro uno o due mesi”. Secondo quanto riportato da Cointelegraph, Musk lo ha descritto come “la fonte centrale di tutte le transazioni monetarie”.
Nel 2023, Musk aveva dichiarato che sarebbe stato “sconvolgente” se X non avesse avuto i trasferimenti di denaro operativi entro fine 2024. Siamo arrivati a febbraio 2026 e forse il progetto tanto ambito da Musk potrebbe arrivare.
Va anche rilevato come X non abbia ancora ottenuto la licenza di trasmissione di denaro nello stato di New York, requisito fondamentale per operare su scala nazionale negli Stati Uniti.
Per Musk si tratterebbe di un ritorno alle origini, dato che nel 1999 aveva co-fondato X.com, poi diventata PayPal. Ma tra le ambizioni dichiarate e la realtà operativa c’è spesso un divario significativo. Le tempistiche di Musk sono notoriamente ottimistiche, e i precedenti suggeriscono cautela.
Il contesto: fusioni, acquisizioni e consolidamento
Il dato sugli abbonamenti arriva in un momento di grande movimento per l’ecosistema di Musk.
Nel marzo 2025, xAI ha acquisito X Corp. in una transazione che valutava il social network 33 miliardi di dollari, circa 12 miliardi in meno rispetto ai 44 pagati nell’ottobre 2022. La settimana scorsa, SpaceX ha acquisito xAI, creando un’entità combinata valutata 1,25 trilioni di dollari.
Nikita Bier, l’uomo che ha annunciato il traguardo del miliardo, è entrato in X come head of product a fine giugno 2025.
È noto per aver creato app virali come TBH e Gas, entrambe acquisite rispettivamente da Meta e Discord. La sua specialità è creare prodotti che generano engagement e conversioni.
Il meeting in cui sono stati annunciati questi numeri arrivava dopo l’uscita di diversi dirigenti da xAI, e aveva tutta l’aria di un esercizio di rassicurazione interna ed esterna.
I numeri nel contesto
I numeri dichiarati da X
Ricavi annualizzati da abbonamenti: 1 miliardo di dollari (proiezione)
Utenti attivi mensili: 600 milioni (o 500 milioni, secondo Bier)
App installate: oltre 1 miliardo
Abbonati Premium stimati a inizio 2025: circa 650.000
Ricavi totali 2024: circa 2,5 miliardi di dollari
Quota ricavi da pubblicità: 68%
Debito ereditato dall’acquisizione: circa 12 miliardi di dollari
Il trend più ampio: tutti verso gli abbonamenti
Il caso di X si inserisce in una tendenza più ampia che coinvolge tutte le principali piattaforme. Come sottolinea un’analisi di Social Media Today, Meta ha lanciato Meta Verified per Facebook, Instagram e Threads. Snapchat ha Snapchat+. LinkedIn sta ampliando la sua offerta Premium. YouTube sta spostando sempre più funzionalità dietro paywall. Instagram sta valutando un’offerta simile a Snapchat+ per i più giovani.
Nel 2023 Musk aveva previsto questa evoluzione, sostenendo che il social a pagamento sarebbe diventato “l’unico social media che conta”. L’argomentazione era legata alla lotta ai bot, ma nell’era dell’intelligenza artificiale generativa quella logica assume contorni diversi.
C’è però un limite strutturale che nessuna piattaforma può ignorare. Il valore pubblicitario dipende dalla massima reach possibile, e la reach evidentemente richiede accesso gratuito per la maggioranza degli utenti.
Nessuna piattaforma digitale può oggi permettersi di passare a un modello interamente a pagamento senza perdere la propria base utenti. E, di conseguenza, il modello ibrido sembra l’unica strada percorribile.
Le contraddizioni dietro i numeri
Quasi contemporaneamente ai momenti in cui veniva annunciato il miliardo dagli abbonamenti, X ha rimosso la modalità “dim” dall’interfaccia desktop, lasciando agli utenti solo la scelta tra sfondo bianco e nero totale. La modalità a luci soffuse, più riposante per gli occhi, non è più disponibile.
Quando gli utenti hanno iniziato a chiedere spiegazioni, la risposta di Nikita Bier è stata rivelatrice: X non può permettersi di supportare “più di due colori”. E alla replica di chi trovava la spiegazione bizzarra, Bier ha chiarito: a differenza di Meta, Google e Microsoft, che hanno decine di migliaia di dipendenti, il team di X che lavora sul prodotto “è di 30 persone”.
E se un miliardo di dollari in abbonamenti non basta a mantenere tre opzioni di colore, qualche domanda sulla sostenibilità del modello è legittima.
Il vero punto della questione di X
Il miliardo di dollari dagli abbonamenti è un dato che va registrato, certo. Ma va anche contestualizzato. Come ho cercato di spiegare qui, si tratta di una proiezione, non un consuntivo.
Arriva da un’azienda che non pubblica bilanci e che ha una storia di numeri presentati in modo selettivo. Si inserisce in una strategia che punta a ridurre la dipendenza dalla pubblicità, ma che finora non ha raggiunto gli obiettivi dichiarati.
X sta cambiando, questo è ormai evidente a tutti ed è anche scontato ripeterlo. Ma la direzione non è ancora chiara, e le dichiarazioni di Musk hanno un andamento che invita alla prudenza.
Per fornire le migliori esperienze, utilizziamo tecnologie come i cookie per memorizzare e/o accedere alle informazioni del dispositivo. Il consenso a queste tecnologie ci permetterà di elaborare dati come il comportamento di navigazione o ID unici su questo sito. Non acconsentire o ritirare il consenso può influire negativamente su alcune caratteristiche e funzioni.
Funzionale
Sempre attivo
L'archiviazione tecnica o l'accesso sono strettamente necessari al fine legittimo di consentire l'uso di un servizio specifico esplicitamente richiesto dall'abbonato o dall'utente, o al solo scopo di effettuare la trasmissione di una comunicazione su una rete di comunicazione elettronica.
Preferenze
L'archiviazione tecnica o l'accesso sono necessari per lo scopo legittimo di memorizzare le preferenze che non sono richieste dall'abbonato o dall'utente.
Statistiche
L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici.L'archiviazione tecnica o l'accesso che viene utilizzato esclusivamente per scopi statistici anonimi. Senza un mandato di comparizione, una conformità volontaria da parte del vostro Fornitore di Servizi Internet, o ulteriori registrazioni da parte di terzi, le informazioni memorizzate o recuperate per questo scopo da sole non possono di solito essere utilizzate per l'identificazione.
Marketing
L'archiviazione tecnica o l'accesso sono necessari per creare profili di utenti per inviare pubblicità, o per tracciare l'utente su un sito web o su diversi siti web per scopi di marketing simili.